
One of the primary challenges of any ML/AI project is transitioning it from the hands of data scientists in the develop phase of the data science lifecycle into the hands of engineers in the deploy phase.
Where in the life cycle does data scientists’ involvement end? Who takes responsibility for the operationalized models? And how long should the transition between development and deployment last? What does a data scientist do, compared to a data engineer or a DevOps engineer?
The answers to these questions are seldom cut and dried, even in a small shop. For an enterprise, the questions can become even more complicated as you add additional team members, each with different roles, into the mix.
The Enterprise MLOps Process Overview
The data science lifecycle encompasses four phases that provide a thumbnail sketch of the overall process and indicate where different team members should be focusing.
- Manage: The Manage stage focuses on understanding the objectives and requirements of the project and prioritizing the work. Data scientists engage with the business, leadership, end users, and data experts to scope the project, estimate value, estimate costs, blueprint a solution, create mock deliverables, create goals, agree on timeline and validation and approval gates. They document this work for the benefit of future data scientists and auditors alike.
- Develop: The Develop stage is where data scientists build and assess various models based on a variety of different modeling techniques. Data scientists create a model and test it with algorithms and data. They may rely on, or be assisted by, the data analysts. Data engineers assist by providing clean data. Infrastructure engineers assist by providing the IT infrastructure for data scientists to work. Data experts are called in when data scientists need help understanding complex relationships that exist in the data.
- Deploy: The Deploy stage is where data scientists build and assess various models based on a variety of different modeling techniques. The tested model is transitioned from the data scientists to DevOps and infrastructure engineers in a production environment. If the model needs to be rewritten into another language the software developer takes over.
- Monitor: The Monitor stage is the operational phase of the lifecycle where organizations ensure that the model is delivering the expected business value and performance. The model is usually monitored by engineers, bringing in the data scientists as needed if problems arise. If it’s not behaving as predicted, the data scientists troubleshoot the model. The data engineers assist if problems arise in the data pipeline. Both then use the information learned, as well as the resources, in the next development phase.
However, the roles and responsibilities in the typical lifecycle are seldom this clearly delineated.
7 Key Roles in an MLOps Team
In smaller data science operations, it’s possible for one person to have more than one role, but in an enterprise each team member should be able to focus on their specialty. There are seven primary roles, although there are usually several others involved. The business manager, for example, would be involved in the ideation and validation stages, while someone on the legal team would oversee the project for compliance before the model is delivered.
1. Data Scientist
Often seen as the central player in any MLOps team, the Data Scientist is responsible for analyzing and processing data. They build and test the ML models and then send the models to the production unit. In some enterprises, they are also responsible for monitoring the performance of models once they are put into production.
2. Data Analyst
The data analyst works in coordination with product managers and the business unit to uncover insights from user data. They typically specialize in different types of tasks, such as marketing analysis, financial analysis, or risk analysis. Many have quantitative skills comparable to those of data scientists while others can be classified as citizen data scientists that have some knowledge of what needs to be done but lack the coding skills and statistical background to work alone as data scientists do.
3. Data Engineer
The Data Engineer manages how the data is collected, processed and stored to be imported and exported from the software reliably. They may have expertise in specific areas, like SQL databases, cloud platforms, as well as particular distribution systems, data structures, or algorithms. They are often vital in operationalizing data science results.
4. DevOps Engineer
The DevOps engineer provides data scientists and other roles with access to the specialized tools and infrastructure (e.g., storage, distributed compute, GPUs, etc.) they need across the data science lifecycle. They develop the methodologies to balance unique data science requirements with those of the rest of the business to provide integration with existing processes and CI/CD pipelines.
5. ML Architect
The ML Architect develops the strategies, blueprints and processes for MLOps to be used, while identifying any risks inherent in the life cycle. They identify and evaluate the best tools and assemble the team of engineers and developers to work on it. Throughout the project life cycle, they oversee MLOps processes. They unify the work of data scientists, data engineers, and software developers.
6. Software Developer
The Software Developer works with data engineers and data scientists, focusing on the productionalization of ML models and the supporting infrastructure. They develop solutions based on the ML architect's blueprints, selecting and building necessary tools and implementing risk mitigation strategies.
7. Domain Expert/Business Translator
A Domain Experts/Business Translator has deep in-depth knowledge of business domains and processes. They help the technical team understand what is possible and how to frame the business problem into an ML problem. They help the business team understand the value offered by models and how to use them. They can be instrumental in any phase where a deeper understanding of the data is crucial.
Possible Pain Points in the MLOps Process
With so many stages in the process and so many people involved in an enterprise operation, communication and collaboration between teams and between silos can quickly create a number of problems. For instance, problems arise when teams do not understand what data was used for which model, where the data originated and how it is being tracked. This creates reliance on the data scientist(s) to provide all the necessary information and manage the transition from one stage to the other, which becomes an issue of data science governance. Problems arise when changes and progress in the MLOps process are not properly documented, which can create inaccurate datasets and overall confusion for team members.
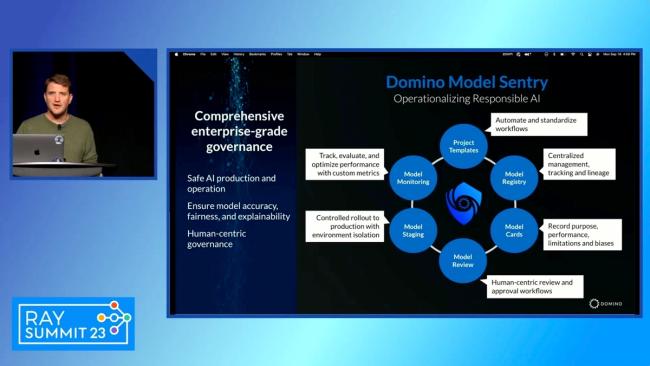
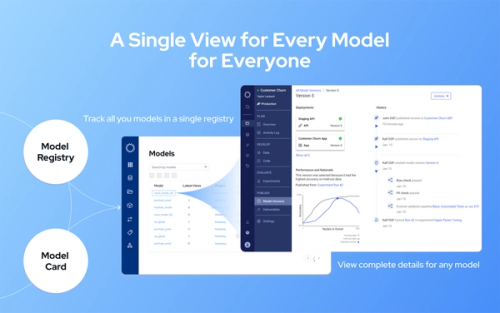
A key point is ensuring that models are efficiently transitioned from one stage to another, without key information from previous stages becoming lost. This is accomplished with an Enterprise MLOps platform that simplifies and streamlines the complex data science process. For example, data scientists can easily get access to the tools and computations they need without having to rely on an Infrastructure Engineer.
Establishing Standards to Avoid Mistakes in MLOps
One of the most important facets of managing MLOps well is to ensure each member is aware of their role in the team. Having a data scientist responsible for monitoring the deployment phase of a project instead of an engineer, for example, is relatively easy when they have access to monitoring tools and can be pinged automatically by the MLOps platform when an issue with the model arises.
Each specialization should have a lead assigned who is responsible for signing off on each phase of the project. A lead data scientist, for example, would oversee work done during the testing phase and would be responsible for determining when the model is ready for validation by the business unit.
Domino’s Enterprise MLOps Platform
Using Domino’s Enterprise MLOps platform, team members are able to easily perform their role across the entire data science lifecycle. It shortens the time and effort at key transitions and integrated workflows provide consistency regardless of who is doing the work. It also provides access to automatic monitoring tools and automatically generated reports that require very little time for someone to check in on the progress of a model. Because the needed information is right there at their disposal, the additional collaboration doesn’t take time or energy away from other tasks at hand.


David Weedmark is a published author who has worked as a project manager, software developer and as a network security consultant.

Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.