Domino 5.0: Develop Better Models Faster With Auto-Scaled Distributed Compute
Alireza Mounesisohi and Lakshmi Narayanan2022-02-09 | 8 min read
Introducing On-Demand Autoscaling Clusters in Domino 5.0
By Alireza Mounesisohi, Field Engineer at Domino, and Lakshmi Narayanan, Solution Architect at Domino, on February 9, 2022, in Product Updates
Distributed compute clusters provide data scientists with enormous processing power to solve complex problems by testing more ideas, faster. However, taking advantage of this power is challenging because:
- Data scientists have to wait for clusters to become available even though it is often sitting idle on projects.
- Provisioning compute and managing packages for distributed compute frameworks can be complex and time-consuming, and require extensive DevOps skills.
Domino 5.0 helps organizations overcome these barriers with distributed compute autoscaling. With Domino 5.0:
- Compute clusters, including the most popular distributed compute cluster types Spark, Ray, and Dask, dynamically grow and shrink based on the workload, improving data scientist productivity by ensuring compute resources are available to any project that needs them.
- Eliminate the need to commit resources based on the anticipated peak load, leading to cost savings.
How it Works
Autoscaling of Compute Nodes
One of the most common use cases of autoscaling in Domino is when users have different machine learning workloads and need different compute resources. With the benefit of Kubernetes, users can have different node pools, each containing different types of instances. Domino takes advantage of the capabilities of Kubernetes to autoscale compute nodes so they are only live when in use.
For scaling out, Domino constantly looks for unavailable resources at a given frequency. If no resources are available, Domino scales up the number of nodes to accommodate the resource request.
To illustrate, in Figure 1 below, the non-GPU workspaces created within Domino will run on the node pool “default”. Note that the instances listed here are of type “m5.2xlarge” and the node pools are only “default” and “platform”.
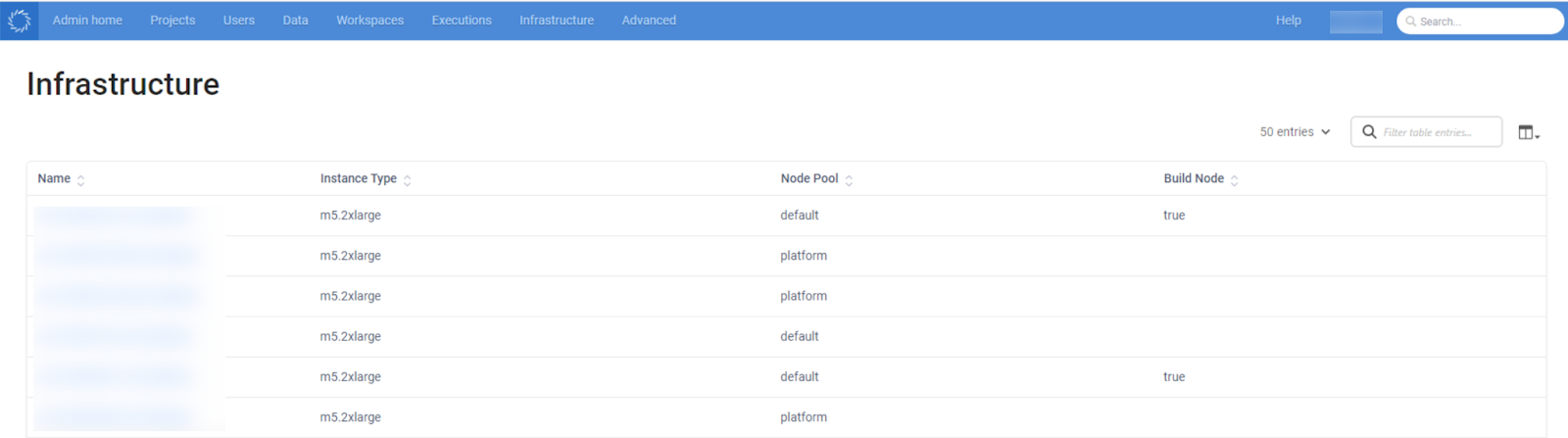
Figure 1: Domino Dashboard of Nodes in Use
Nodes that have the same value for the “dominodatalab.com/node-pool” Kubernetes node label form a Node Pool. Executions with a matching value in the Node Pool field will then run on these nodes. Domino relies on the labeling of the nodes in the underlying node pools associated with the Kubernetes cluster to scale compute nodes. Additionally, Hardware Tiers control the underlying machine type on which a Domino execution will run.
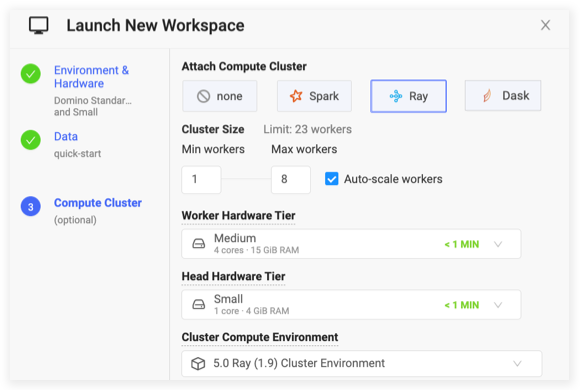
Now, imagine starting a new GPU workspace (Figure 2). Domino will run the workspace on nodes with the underlying node pool labeled “default-gpu”.
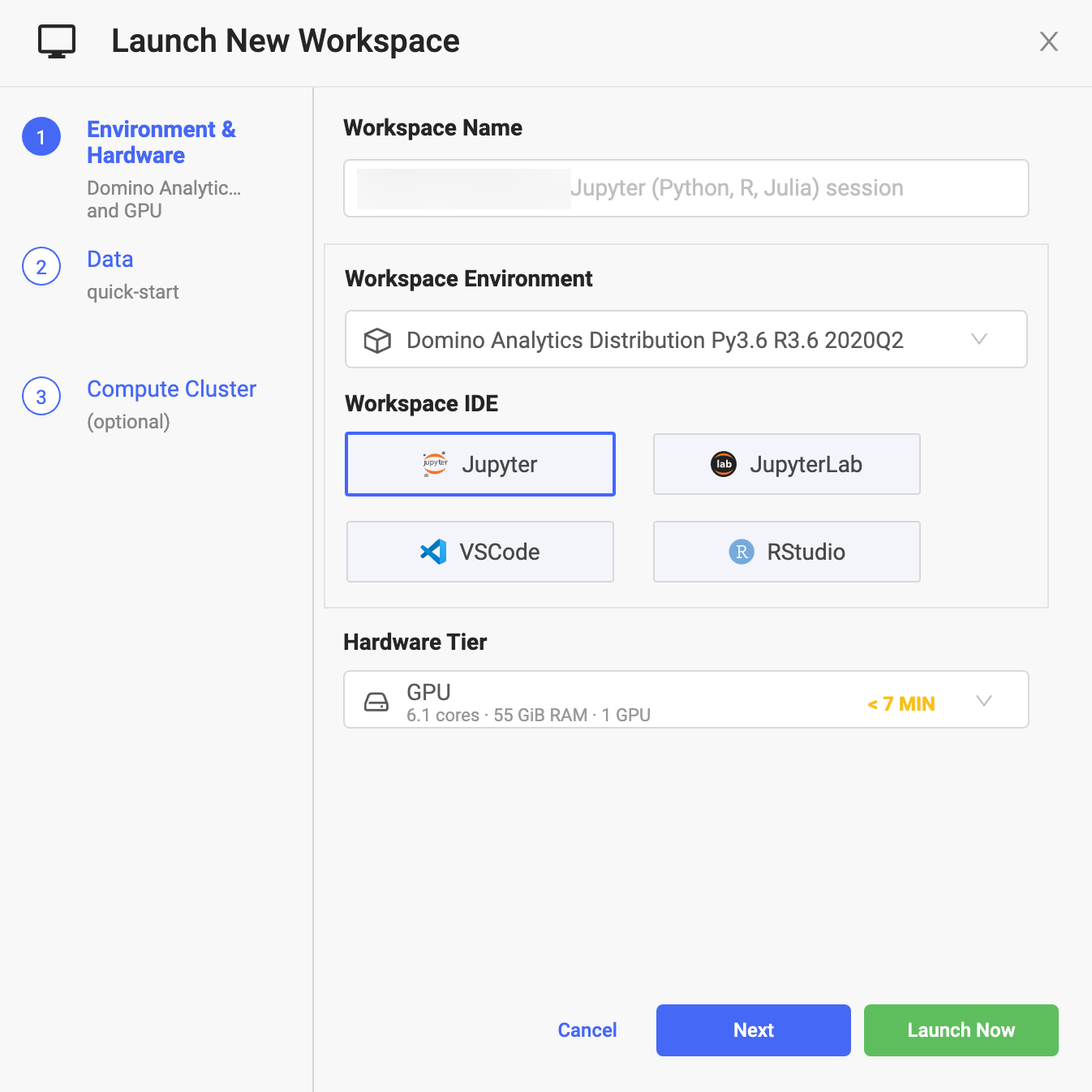
Figure 2: Creating a new workspace with the GPU Hardware tier
Creating this workspace will trigger a scale up of the GPU compute node from 0 -> 1. (Figure 3)
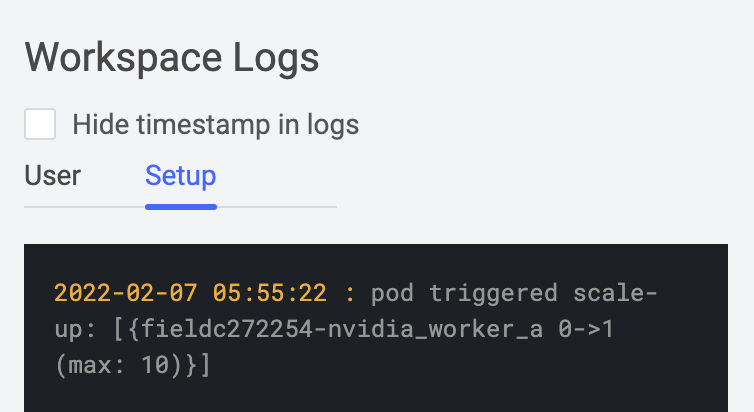
Figure 3: The cluster autoscaler will trigger a scale-up of the GPU node from 0 -> 1
Once the cluster autoscaler scales up the new node and it’s attached to the Kubernetes cluster (Figure 4), the workspace pod gets scheduled to the new node
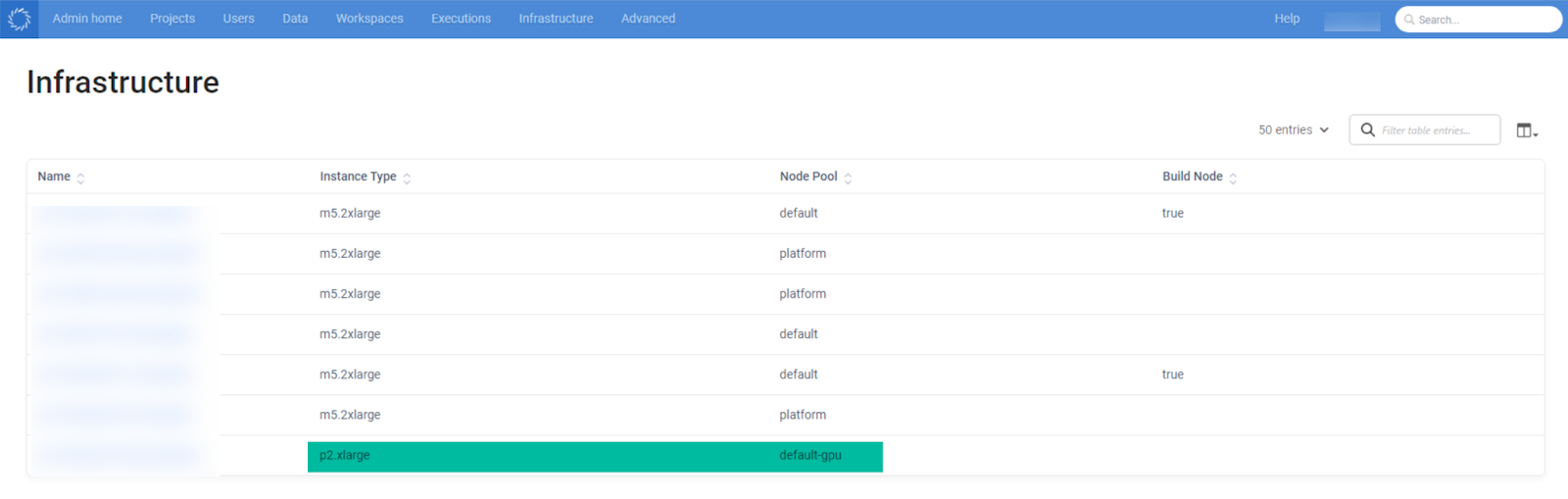
Figure 4: The new node listed under the Infrastructure section of Domino
The cluster autoscaler keeps track of resource requests on a node. If a node is not utilized for 10 minutes (configurable), it will be terminated.
A node is deemed to be unneeded if all of the following conditions are met:
- The sum of CPU and memory requests of all pods running on this node is smaller than 50% of the node's allocatable capacity (note: this threshold is configurable)
- All pods running on the node can be moved to another node
- There is no annotation set to disable scaling down (Reference)
As a result, Domino efficiently balances the number of resources with the demand at any given time.
Autoscaling Across Distributed Compute Frameworks
In addition to autoscaling of the compute nodes using cluster autoscaler, Domino 5.0 has the capability to autoscale Spark, Ray, and Dask on-demand clusters. This is will enable the data scientist to begin with a small cluster and scale as needed based on the fluctuating demands of the job.
Domino leverages the horizontal pod autoscaling capabilities provided by Kubernetes and supports distributed cluster autoscaling for Spark, Ray, and Dask clusters. When the average CPU/memory utilization across all workers exceeds 80 percent (or the target set by an administrator) a scale-up operation is triggered up to the maximum worker count configured for the cluster. When the average utilization falls below the target, a scale down is triggered.
A user can set up a cluster with auto-scaling distributed compute with just a few clicks. As shown in Figure 5, Domino will spin up a cluster with three Dask workers and if the average CPU/memory utilization exceeds the configured value, the number of workers will be scaled up to a maximum of five workers.
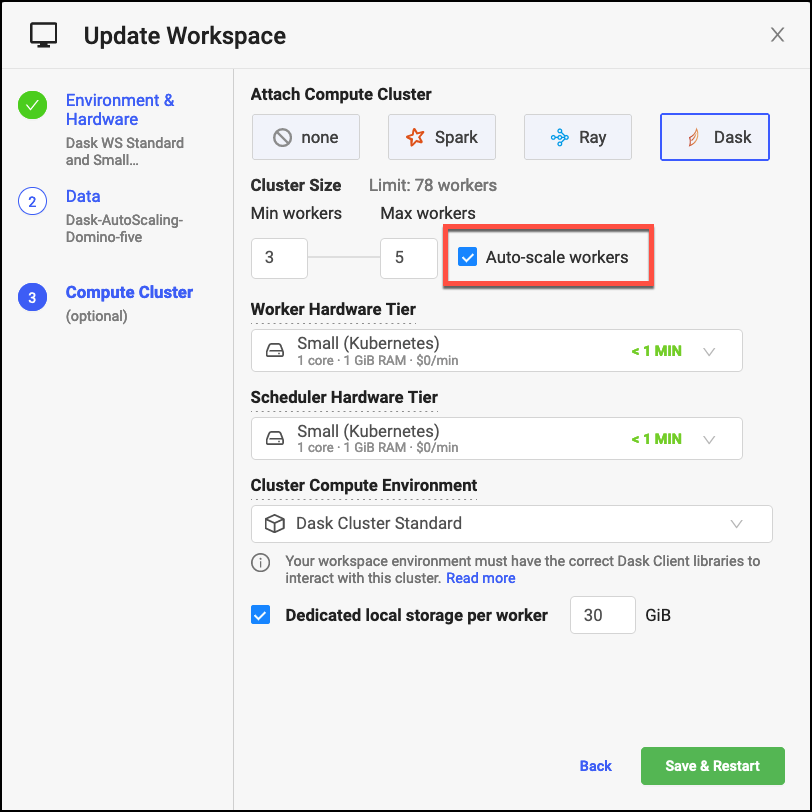
Figure 5: Enabling Auto Scaling of distributed clusters in Domino
Domino will keep adding workers until the max worker limit is reached. Figure 6 shows an example where a cluster started with one worker and scaled up to five workers as the resource utilization thresholds were exceeded.
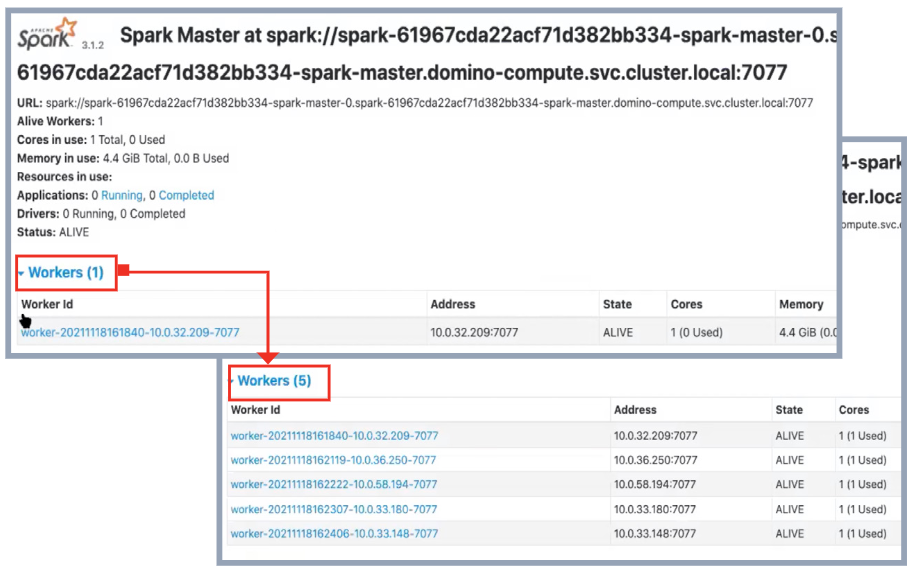
Figure 6: Example of Scaling Up Resources on a Spark Cluster
Conclusion
Access to scalable compute infrastructure is critical for data scientists to do what they do best. Domino empowers data scientists by taking care of the underlying computing needs, using Kubernetes to scale the distributed compute cluster. In addition, IT teams managing the infrastructure can rest easy knowing that the Kubernetes Cluster Autoscaler will only spin up nodes when necessary, saving the organization from wasting money on underutilized resources.
A critical component of increasing model velocity is streamlining the utilization of clusters. Domino automatically scales compute clusters based on the workload to simplify provisioning, optimize utilization, and manage computing costs so you can maximize the productivity of your teams and of the return on your computing investments.
Domino is the Enterprise MLOps platform that seamlessly integrates code-driven model development, deployment, and monitoring to support rapid iteration and optimal model performance so companies can be certain to achieve maximum value from their data science models.
About the Author
Alireza Mounesisohi is a Field Engineer on the customer success team at Domino.
He holds a PhD in Mechanical and Aerospace Engineering from UC Davis and has an extensive background in data science and machine learning.
Lakshmi Narayanan is a Solution Architect with the customer success team at Domino.
He primarily serves Domino customers, providing architectural guidance and leading practice recommendations for new and existing Domino installation/upgrades. Outside of work, he enjoys outdoor activities like hiking and is glued to FIFA.
RELATED TAGS
SHARE



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.