The wildfire spread of the coronavirus across 188 countries around the globe has been catastrophic. So far it has infected 74 million people, killing 1.6 million of them, and is expected to cause 2020 global GDP to contract by anywhere between 4.5 percent and 5.2 percent – roughly $4 trillion to $5 trillion US dollars.
One of the harder to observe effects of COVID-19 has been its impact on AI models. For all the advantages AI offers, AI applications are not infallible. Arguably the most common way machine learning models fail over time is when the data they were trained on no longer reflects the present state of the world. While most AI models degrade gradually, COVID-19 has abruptly degraded AI models in applications ranging from online shopping to forecasting airline passenger volumes to correctly understanding what an image depicts.
How a machine learning model works
An AI model automates a decision-making process by recognizing patterns that match inputs to outputs such as “if x then y.” To learn these patterns in a generalized manner, AI models require training on a large dataset (called a training set), sometimes combined with expert human input. In this way, an AI model is trained to reach decisions that an expert human would make with the same set of data. Typically the larger the dataset available to train an AI model, the more accurate it will be.
What is drift and how does it affect AI models?
Data drift or model drift is a concept which refers to the degradation of a model’s accuracy over time. Entropy always increases over time, so every model’s performance degrades over time, regardless of your model’s quality metric – mean error rate, accuracy, or something else. For some models, the environment is sufficiently isolated and/or stable that it can last years without needing to correct for drift. For most models however, retraining needs to happen more often, sometimes on a daily basis.
How COVID-19 quickly infected AI models worldwide
If AI is only as good as the data used to train it, when a black swan event hits, it changes human behavior in ways that invariably make the dataset in an AI model redundant. Some dramatic examples of COVID’s impact on data science models include:
Instacart’s instaproblem
Online grocery shopping service Instacart used a data science model that usually enjoyed a 93 percent accuracy rate for predicting whether a particular product would be available at a given store. In March 2020, that accuracy rate suddenly plunged to 61 percent after customers drastically changed their shopping behavior in the face of the nascent pandemic.
Grocery shoppers would typically buy things like toilet paper only sporadically. Within the space of about a week they were wiping out store supplies of goods such as toilet paper, hand sanitizer, eggs, flour, and other household essentials as citizens moved to stockpile in case supply chains broke down.
Instacart adapted by changing the timescale of the shopping data it fed into its AI models from weeks to only ten days, making its models more responsive to quickly changing shopping habits. They made a tradeoff between the volume of data used to train their model and the “freshness” of data, Instacart’s machine learning director Sharath Rao told Fortune magazine.
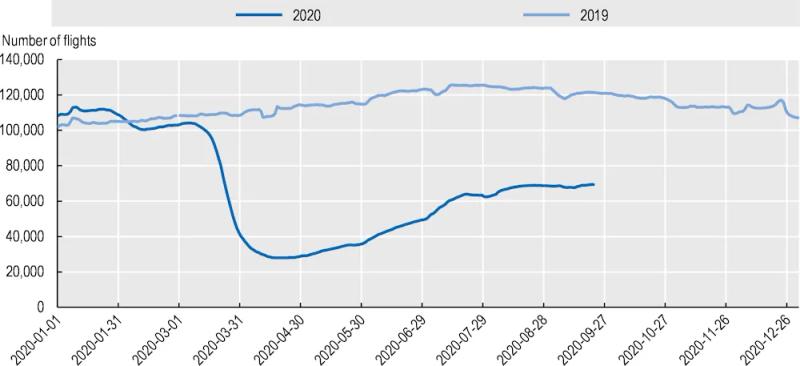
Airline passenger volumes
Normally, AI models predict future global air passenger volumes with a high degree of precision. But with COVID-19 causing catastrophic data drift, no models were able to predict a 90 percent year-on-year decline in passenger air transport for April 2020. While flights have recovered slightly, overall this year has been devastating for the aviation industry. Entire passenger air fleets have been put into storage, with millions of workers furloughed or laid off.
Reading pictures wrongly
Getty Images sells stock images, photos, and videos to creative professionals, news media, and corporations, and maintains a library of over 200 million assets. For customers to find the right image, Getty uses extensive tagging and accurate taxonomies to empower customers’ search. But COVID-19 fundamentally changed how hundreds of millions of humans work, play, and dress, resulting in computer vision models struggling to understand new social and cultural norms and to appropriately tag depictions of new scenes and situations.
Getty Images Head of Data Science Andrea Gagliano laid out the problem to TechCrunch. Say you have a picture of a father working on his laptop at home while his son plays beside him. Getty’s AI models categorize this as “leisure” or “relaxation” rather than “work” or “office,” despite the overwhelming majority of white collar workers now working from home. Or think of masks – with so many faces now wearing masks, AI models are struggling to accurately identify and categorize people wearing masks. They will detect faces as solely the top half of the face, or recognize the mask and the eyes as two separate faces.
Can AI models respond to black swan events like COVID-19?
It’s impossible to foresee all relevant future events and build an AI model that will be resilient to black swan occurrences.
What you can do is detect when a model goes astray, and create a process for deciding if it needs immediate retraining or decommissioning. This way it won’t silently continue making ostensibly well-informed but actually inaccurate predictions.
Most data science teams do not actively monitor drift, although some teams do sporadic and ad-hoc testing. More recently some data science teams have begun to use dedicated model monitoring tools that automate the process of detecting drift, retraining the model, and deploying an updated model. These tools not only detect a non-performing model, they instantly notify data scientists so they can take corrective action.

RELATED TAGS
SHARE



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.