Reinforcement Learning Introduction: Foundations and Applications
Nikolay Manchev2021-10-28 | 17 min read

Introduction
When we think about learning, we are often tempted to focus on formal education that takes place during childhood and adolescence. We often think of textbooks, lectures, homework, and exams as the building blocks of the process of acquiring new knowledge, skills, and understanding. However, the ability to learn is not an ability exclusive to humans and certainly isn’t constrained to a strictly academic setting or to a certain period of a person’s life. Indeed, the ability to learn is universally present across humans, animals, and even plants (Karban, 2015), and is an ongoing process that takes place continually. On the other hand, learning is a hypothetical construct. As Gross (2010) points out, “learning cannot be directly observed, but only inferred from observable behavior.”
Psychologists have proposed several different theories over the years, to explain how the process of learning takes place. One of the earliest theories of learning was developed by the Russian physiologist Ivan Pavlov (1849-1936), while he was studying the digestive system of dogs. Pavlov noticed that the dogs would salivate when they spot the technician responsible for feeding them, but before they had seen any actual food. After conducting a number of experiments, Pavlov identified a fundamental behavioral mechanism known as classical conditioning. In essence, classical conditioning occurs when a subject learns to associate a previously neutral stimulus (e.g. a bell) with a biologically potent stimulus (e.g. food). Figure 1 outlines the approach developed by Pavlov to demonstrate that a strong conditioned stimulus could be used to produce an automatic, biologically built-in response.
Classical and Operant Conditioning - The Foundations of Reinforcement Learning
The behaviorist B. F. Skinner’s book “The Behaviour of Organisms: An Experimental Analysis” (Skinner, 1938) proposed a different type of associative learning process called operant conditioning. In his book, Skinner argued that behavior triggered by specific stimuli cannot alone account for everything. Instead, he looked into how animals and humans interact with their environment and how the consequences of them performing certain operations drive the probability of repeated behaviour. Skinner performed a series of experiments using a type of laboratory apparatus he created, which is now known as an operant conditioning chamber. The chamber setup enables experimenters to study the response of an animal to certain stimuli, such as light or sound. It also provides a mechanism for the animal to undertake specific actions, for example by pressing a lever, and can dispense rewards (e.g. food) or deliver punishments (e.g. electric shock). The chamber is typically used with rats or pigeons. It is important to highlight that performing experiments using an operant conditioning chamber is substantially different from the classical conditioning experiments of Pavlov. Unlike the respondent behaviors that occur automatically and reflexively, operant behaviors are under the subject’s conscious control. The operant conditioning theory demonstrates that some types of behavior can be modified by using reinforcements and punishments. Reinforcements can either be positive or negative, but they always act in a way that strengthens or increases future behavior.
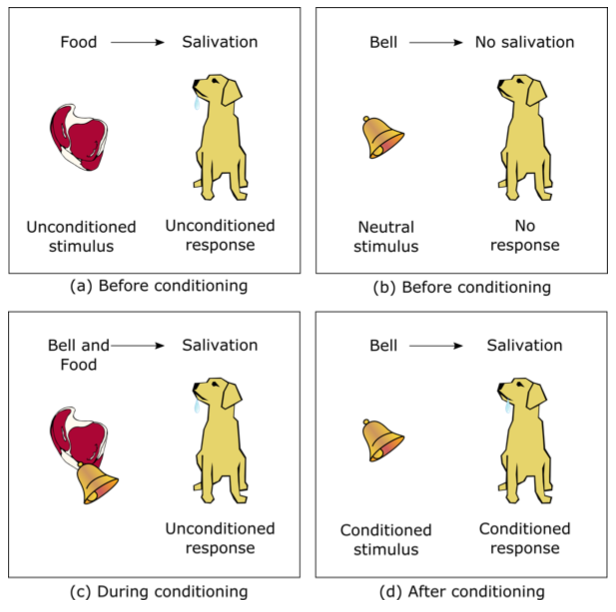
Figure 1: Classical conditioning: (a) Before conditioning, the presence of food will naturally make the dog salivate; (b) A stimulus (such as a bell) that wouldn’t normally produce salivation response is selected; (c) During conditioning, the sight of food is paired with the sounding of the bell. This is repeated until conditioning has taken place; (d) After conditioning, the sound of the bell alone triggers a salivation response, which is now referred to as a conditioned response.
- Positive reinforcement involves the invocation of pleasurable stimuli. For example, when the rat presses the lever, it receives a treat. The treat acts as positive reinforcement and prompts the rat to press the lever more often.
- Negative reinforcement involves the removal of unfavorable events after the display of the desired behavior. For example, a teacher can cancel that night’s homework if the students achieve a certain target in class. Here, the homework serves to negatively reinforce the behavior of working in class, because the students want to remove that aversive stimulus of having to do homework in the evening.
The examples above demonstrate that reinforcement always leads to an increase (or strengthening) of the desired behavior. In the first example, the rat is conditioned to press the lever more often, and in the second example, the students are conditioned to work harder in class. Punishments, on the other hand, serve to weaken a behavior. They can also be split into negative and positive, with negative punishments involving the removal of a favorable event (e.g. taking a child’s toy away) and positive punishments involving the introduction of an unpleasant factor (e.g. assigning extra work to students who don’t turn in their assignments on time).
What is Reinforcement Learning?
Reinforcement learning (RL) is an area of machine learning concerned with various techniques that enable an intelligent agent to learn through interaction with its environment. This process is largely based on trial and error, where the agent learns to take specific actions that maximize a reward associated with some desired behavior.
We could easily see the parallels that such definition brings with running an experiment in an operant conditioning chamber. An animal in the chamber (an agent) inspects its surroundings (perceives its environment), activates the leaver (takes an action), and receives a food pellet (reward). As interesting, or challenging, interacting with animals could be, when we talk about reinforcement learning in the context of machine learning, we will limit ourselves to intelligent agents in the form of a program. A simple implementation of such a program could follow a basic interaction loop like the one depicted in Figure 2. We need to be careful, however, not to think about intelligent agents only in terms of robots or systems performing complex tasks with long-term goals. A smart, self-learning thermostat that gets temperature readings from its environment, takes an action to adjust the heating and receives awards based on the delta between actual and desired temperature is a perfectly viable example of an intelligent agent.
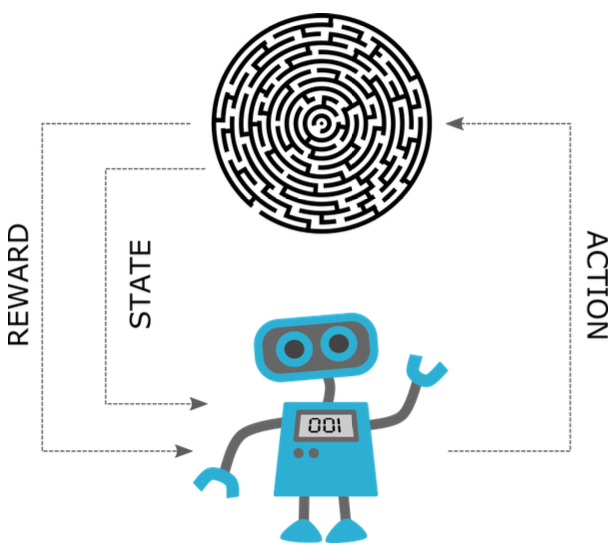
Figure 2: Simple reinforcement learning loop — the agent reads the state of the environment; the agent takes an action based on the current state; the agent receives a reward; the environment is now into a new state, and the process repeats.
Reinforcement Learning and Machine learning
Speaking of machine learning, we also need to specify the differences between reinforcement learning and other established training methods like supervised and unsupervised learning.
- In supervised learning, the goal is to learn a mapping from inputs x to outputs y, given a labeled set of input-output pairs \(D = \{(x_i, y_i)\}_{i=1}^N\) (Murphy, 2013). Models learned using supervised learning are often called predictive models because they output the target variable y for some input x. The key point here is that the availability of labeled data is a necessity — supervised learning cannot learn the input-output mapping without the presence of labeled data, which is typically gathered from human experts or from sensor-collected measurements. Such a requirement is not present in reinforcement learning; the reward is sufficient to give the agent an idea of its own performance. In a sense, the agent generates its own training data by interacting with the environment, hence it doesn’t need an expert trainer.
- The goal in unsupervised learning is to find “interesting patterns” in the data (Murphy, 2013). In this case, we are not provided with pre-assigned outputs nor are we told anything about what even constitutes an interesting pattern. Because such models do not output a target variable, they are typically called descriptive models. Strictly speaking, this is not what reinforcement learning is about — the agent is aiming to maximize the reward signal, not to explicitly expose patterns in its experience or describe existing data.
With the above in mind, we can clearly see why reinforcement learning is typically considered a separate area in the domain of machine learning. Yes, much like unsupervised learning, reinforcement learning requires no supervision during training, but this is where the similarities end. The ultimate goal of the agent is to make a sequence of decisions that will lead to achieving a certain goal while operating under uncertainty in a complex and often dynamically changing environment. In addition, the agent uses a “trial end error” approach and, in contrast to supervised learning, suboptimal actions are not explicitly corrected.
Moreover, reinforcement learning has a much wider outreach and is not exclusively constrained to the realm of machine learning. Research in the interdisciplinary field of neuroeconomics suggests that the brain relies on model-free biological algorithms for operant learning (Montague et al., 2004). Model-free reinforcement learning has been used in the field of computational psychiatry for the purposes of diagnosing neurological disorders (Maia & Frank, 2011; Yechiam et al., 2005). It has been also suggested that hierarchical model-based mechanisms might play a pivotal role in human decision-making (Botvinick & Weinstein, 2014). Reinforcement learning is used in behavioural game theory as a modelling framework for behavioural predictions (Albaba & Yildiz, 2021). Problems from operations research, which aim to model information uncertainty over time, can leverage reinforcement learning techniques like Markov decision processes. There are dedicated reinforcement learning software libraries that address operations research problems (Hubbs et al., 2020). Furthermore, Markov decision processes are heavily used in optimal control theory, and even some terms from reinforcement learning are interchangeably used in optimal control tasks. Reinforcement learning is also very closely related to dynamic programming, stochastic programming, simulation-optimization, stochastic search, and optimal stopping (Powell, 2012).
Use Cases for Reinforcement Learning
The fact that many essential elements from various fields underlie the theory of reinforcement learning has led to the application of its techniques to a broad range of real-world use-cases. Here is a non-exhaustive list of some common use-cases.
- Reinforcement learning can be employed for a wide variety of physical systems and control tasks in robotics (Kober et al., 2013).
- Many industrial processes feature automated subsystems, which are usually good candidates for reinforcement learning-based control and optimisation. There are specialised reinforcement learning algorithms for product manufacturing optimisation like SMART (Mahadevan & Theocharous, 1998), and it has been shown that reinforcement learning outperforms state-of-the-art black-box models in tasks like optimisation of chemical reactions (Zhou et al., 2017).
- Content recommendation is another challenging problem. Established models tend to focus predominantly on modelling current reward (i.e. click-through rate), they are trained on very narrow targets (i.e. click/no-click), and most importantly their recommendations gravitate around similar types of content. On the other hand, reinforcement learning models like DRN (Zheng et al., 2018) model future rewards explicitly and, because of the innate exploration capability of reinforcement learning, can find new and attractive content to keep the users engaged.
- Reinforcement learning can successfully solve problems in Natural Language Processing (NLP) like text summarization (Paulus et al., 2017), machine translation (Grissom II et al., 2014), and dialogue generation (Li et al., 2016)
- Reinforcement learning has an advantage in time-series analysis and modelling trading games in particular, because in such a context taking a high-value action often depends on future actions and states. Such a setting can be very challenging for modelling using conventional supervised learning approaches (Gao, 2018).
- Video gaming is an area where reinforcement learning has attracted considerable attention, mostly because reinforcement learning models have consistently achieved a super-human performance in a large number of games (Shao et al., 2019).
The list above is by no means exhaustive, but it is a testament to the breadth of tasks that can be addressed using reinforcement learning. Indeed, there are myriad frameworks that implement a diverse number of reinforcement learning algorithms. Some frameworks worth mentioning are Acme, RLlib, Dopamine, Tensorforce, Keras-RL, and Stable Baselines.
One of the key value propositions of the Domino Enterprise MLOps Platform is that it accelerates research with self-service scalable compute and tools. Because the platform provides a straightforward way to add and update libraries, tools, and algorithm packages, all of the aforementioned frameworks, including RLlib, which facilitates GPU-accelerated model training on multi-node clusters, can be easily accessed and used for solving reinforcement learning tasks.
Further reading and resources
- Read our previous post on Deep Reinforcement Learning
- Reinforcement Learning: An Introduction by Sutton and Barto is considered to be "the bible" of reinforcement learning, and is freely available online.
RLlib is an open-source library for reinforcement learning that natively supports TensorFlow, TensorFlow Eager, and PyTorch and is considered one of the most powerful in terms of scalability as it is underpinned by Ray.
References
Gross, R. (2010). Psychology: The science of mind and behavior 6th edition (6th ed.). Taylor & Francis.
Karban, R. (2015). Plant sensing and communication. University of Chicago Press
Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. Appleton-Century- Crofts.
Murphy, K. P. (2013). Machine learning: A probabilistic perspective. MIT Press.
Maia, T. V., & Frank, M. J. (2011). From reinforcement learning models to psychiatric and neurological disorders. Nature neuroscience, 14(2), 154–162.
Montague, P., Hyman, S., & Cohen, J. (2004). Computational roles for dopamine in behavioural control. Nature, 431(7010), 760–767. https://doi.org/10.1038/nature03015
Yechiam, E., Busemeyer, J. R., Stout, J. C., & Bechara, A. (2005). Using cognitive models to map relations between neuropsychological disorders and human decision-making deficits. Psychological Science, 16(12), 973–978.
Botvinick, M., & Weinstein, A. (2014). Model-based hierarchical reinforcement learning and human action control. Philosophical Transactions of the Royal Society B: Biological Sciences, 369(1655), 20130480. https://doi.org/10.1098/rstb.2013.0480
Albaba, B. M., & Yildiz, Y. (2021). Driver modeling through deep reinforcement learning and behavioral game theory. ArXiv, abs/2003.11071.
Hubbs, C. D., Perez, H. D., Sarwar, O., Sahinidis, N. V., Grossmann, I. E., & Wassick, J. M. (2020). Or-gym: A reinforcement learning library for operations research problems.
Powell, W. B. (2012). Technical report: Ai, or and control theory: A Rosetta stone for stochastic optimization. technical report (tech. rep.). Princeton University.

Nikolay Manchev is the Principal Data Scientist for EMEA at Domino Data Lab. In this role, Nikolay helps clients from a wide range of industries tackle challenging machine learning use-cases and successfully integrate predictive analytics in their domain specific workflows. He holds an MSc in Software Technologies, an MSc in Data Science, and is currently undertaking postgraduate research at King's College London. His area of expertise is Machine Learning and Data Science, and his research interests are in neural networks and computational neurobiology.
RELATED TAGS
SHARE



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.