Reflections on the Data Science Platform Market
Nick Elprin2019-02-01 | 8 min read

Reflections
Before we get too far into 2019, I wanted to take a brief moment to reflect on some of the changes we’ve seen in the market. In 2018 we saw the “data science platform” market rapidly crystallize into three distinct product segments. This post describes our observations about these three segments and offers advice for folks evaluating products in this space.
Over the last couple years, it would be hard to blame anyone for being overwhelmed looking at the data science platform market landscape. There are dozens of products describing themselves using similar language despite addressing different problems for different types of users. Not only has this confused data scientists, it’s also affected us as a software vendor: some analyses of the market lump Domino together with products completely different from ours, forcing us to answer questions about how we compare to products that address fundamentally different needs and use cases. It has felt, at times, like being an automaker and watching others compare our cars to submarines, airplanes, and scooters.
We’ve been pleasantly surprised to see, over the past six months especially, an emerging clarity in how companies are thinking about these products when equipping their data science teams with best-of-breed technologies. As often happens, this clarity is emerging simultaneously from different corners of the world, reflecting what seems to be the zeitgeist of the data science platform market.
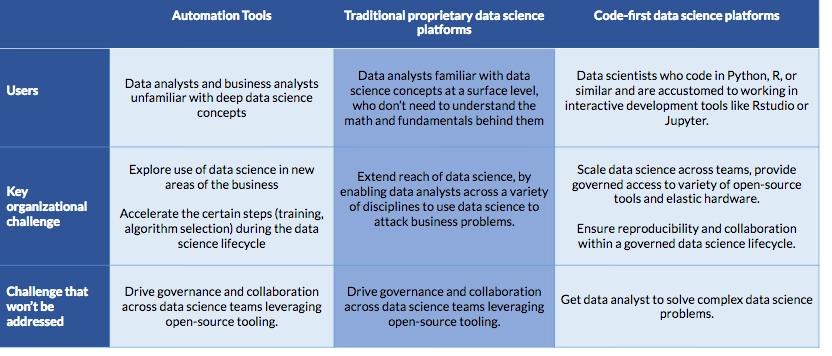
The three segments that have crystallized are:
- Automation tools
- Proprietary (often GUI-driven) data science platforms
- Code-first data science platforms
Automation Tools
These solutions help data analysts build models by automating tasks in data science, including training models, selecting algorithms, and creating features. These solutions are targeted primarily at non-expert data scientists or a data scientist interested in short cutting a tedious steps in their process to build quick baseline models. These “automated machine learning” solutions help spread data science work by getting non-expert data scientists in to the model building process, offering drag-and-drop interfaces. They often include functionality for deploying the models that have been automatically trained, and they are increasingly integrating interpretability and explainability features for those models, as well. They work best when the data is cleanly prepped and consistently structured.
Proprietary (often GUI-driven) data science platforms
These tools support a breadth of use cases including data science, data engineering, and model operations. They provide both drag-and-drop and code interfaces and have strong footholds in a number of enterprises, and may even offer unique capabilities or algorithms for specific micro-verticals. While these solutions offer great breadth of functionality, users must leverage the proprietary user interfaces or programming languages to express their logic.
Code-first data science platforms
This group of solutions targets code-first data scientists who use statistical programming languages and spend their days in computational notebooks (e.g., Jupyter) or IDEs (e.g., RStudio), leveraging a mix of open-source and commercial packages and tools to develop sophisticated models. These data scientists require the flexibility to use a constantly-evolving software and hardware stack to optimize each step of their model lifecycle. These code-first data science platforms orchestrate the necessary infrastructure to accelerate power users’ workflows and create a system of record for organizations with hundreds or thousands of models. Enterprises with teams of data scientists select these solutions to enable accelerated experimentation for individuals while simultaneously driving collaboration and governance for the organization. Key features include scalable compute, environment management, auditability, knowledge management, and reproducibility.
The evidence: what we’re seeing
We’ve seen multiple organizations describe a similar partitioning of the market, at times using slightly different terminology.
For example, the Chief Data Scientist for a top-10 global financial institution told me that their organization had looked at the product landscape and stratified it into three levels based on the technical skill of the intended user:
- “Level 1” included tools that automated data science tasks;
- “Level 2” included tools with drag-and-drop GUIs for less technical analysts;
- “Level 3” was for technical data scientists who wanted to use statistical programming languages to author their logic.
The evaluation team represented these layers as a pyramid: as you moved up the levels, there were a smaller number of users, but the users were more technical and had larger impact. Critically, the levels were not mutually exclusive — in fact, the evaluation ultimately recommended purchasing a tool from each level, to enable the different types of users they had within their organization.
In a similar vein, in 2018 Forrester split apart its “Wave” for predictive analytics products into two distinct Waves. The first — “Multimodal Solutions” — encompasses what we called the “proprietary / GUI-based” solutions in this post (and includes some of the “automation tools”). And their second wave — “Notebook-based Solutions” describes the “code-first” platforms. They have a forthcoming report on automation-focused platforms this year.
As a final example, the 2018 Work-Bench Enterprise Almanac has a great section on machine learning products for the enterprise. In slide 31 they describe three “models for data-driven insights” that align nicely with the three product categories we see:

Image excerpted from 2018 Work-Bench Enterprise Almanac
While solutions from these different segments solve different problems, many organizations need a solution from each of these segments. For example, an insurance company could task a team of expert data scientists to work collaboratively in a code-first platform to develop their proprietary claims risk models. At the same time, they might have a citizen data scientist in the marketing department who is exploring automation tools to see if there is a new approach to lead scoring that provides lift above their existing rules-based process.
The table below summarizes these segments.
Closing thoughts
If you’re considering using any of the products in these segments, our advice (which applies for most technology choices) is to be skeptical of hype and start from an assessment of your business needs, your use cases, and your data science talent strategy. Based on the type of people you’re hiring and how you plan to attack your data science problems — non-technical folks, semi-technical folks, sophisticated technical folks — you will need and want different solutions.
If you pursue a multi-tiered talent strategy for different types of problems, you may need multiple solutions. That may have seemed unpalatable just a year ago, but it makes sense once you see this market landscape as three distinct product categories.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
SHARE


Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.