Subject archive for "k-means-clustering"
Getting started with k-means clustering in Python
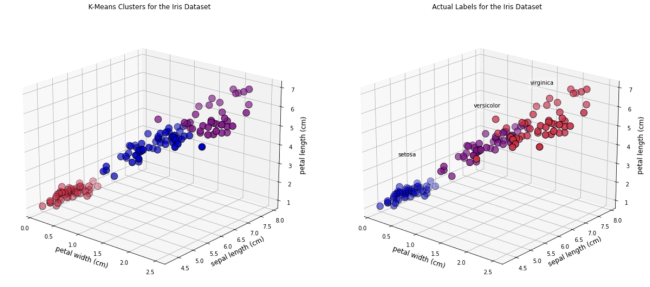
Imagine you are an accomplished marketeer establishing a new campaign for a product and want to find appropriate segments to target, or you are lawyer interested in grouping together different documents depending on their content, or you are analysing credit card transactions to identify similar patterns. In all those cases, and many more, data science can be used to help clustering your data. Clustering analysis is an important area of unsupervised learning that helps us group data together. We have discussed in this blog the difference between supervised and unsupervised learning in the past. As a reminder, we use unsupervised learning when labelled data is not available for our purposes but we want to explore common features in the data. In the examples above, as a marketeer we may find common demographic characteristics in our target audience, or as a lawyer we establish different common themes in the documents in question or, as a fraud analyst we establish common transactions that may highlight outliers in someone’s account.
By Dr J Rogel-Salazar13 min read


Data Quality Analytics
Scott Murdoch, PhD, Director of Data Science at HealthJoy, presents how data scientists can use distribution and modeling techniques to understand the pitfalls in their data and avoid making decisions based on dirty data.
By Domino17 min read
Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.