Subject archive for "model-deployment," page 2

This blog post provides highlights and a full written transcript from the panel, “Data Science Versus Engineering: Does It Really Have To Be This Way?” with Amy Heineike, Paco Nathan, and Pete Warden at Domino HQ. Topics discussed include the current state of collaboration around building and deploying models, tension points that potentially arise, as well as practical advice on how to address these tension points.
By Ann Spencer99 min read

Data Science vs Engineering: Tension Points
This blog post provides highlights and a full written transcript from the panel, “Data Science Versus Engineering: Does It Really Have To Be This Way?” with Amy Heineike, Paco Nathan, and Pete Warden at Domino HQ. Topics discussed include the current state of collaboration around building and deploying models, tension points that potentially arise, as well as practical advice on how to address these tension points.
By Ann Spencer99 min read

Collaboration Between Data Science and Data Engineering: True or False?
This blog post includes candid insights about addressing tension points that arise when people collaborate on developing and deploying models. Domino’s Head of Content sat down with Don Miner and Marshall Presser to discuss the state of collaboration between data science and data engineering. The blog post provides distilled insights, audio clips, excerpted quotes as well as the full audio and written transcript. Additional content on this topic will be forthcoming from additional industry experts.
By Domino32 min read

What Your CIO Needs to Know about Data Science
What would you rather be doing? Data science or DevOps?
By Domino4 min read

Model Deployment Powered by Kubernetes
In this article we explain how we’re using Kubernetes to enable data scientists to deploy predictive models as production-grade APIs.
By Alexandre Bergeron7 min read
“Unit testing” for data science
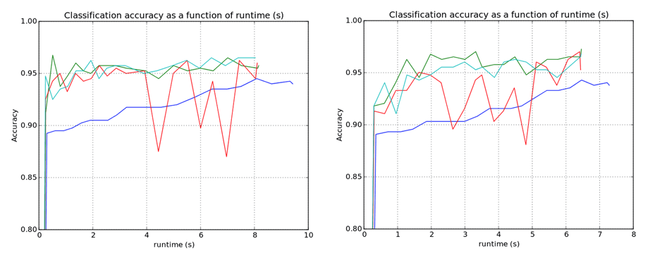
An interesting topic we often hear data science organizations talk about is “unit testing.” It’s a longstanding best practice for building software, but it’s not quite clear what it really means for quantitative research work — let alone how to implement such a practice. This post describes our view on this topic, and how we’ve designed Domino to facilitate what we see as relevant best practices.
By Nick Elprin5 min read
Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.