The Future of Data Science - Mining GTC 2021 for Trends
Josh Poduska2021-04-29 | 18 min read

Deep learning enthusiasts are increasingly putting NVIDIA’s GTC at the top of their gotta-be-there conference list. I enjoyed mining this year’s talks for trends that foreshadow where our industry is headed. Three of them were particularly compelling and inspired a new point of view on transfer learning that I feel is important for analytical practitioners and leaders to understand. Let’s start with the themes.
Expect Deep Learning APIs to get Much Smarter
Summary: APIs will get better at transferring model components from one application to another and transferring pipelines to production.
There is a deep net architecture race going on which may cause deep nets to look quite a bit different 10 years from now
Two examples of novel deep net architectures reviewed below both borrow heavily from the concepts of transformers and BERT-like models that lend themselves so well to transfer learning, however, they do so in a way that can be generalized to other applications like computer vision. I see a future of deep learning where transfer learning is king in large part because mega-model architectures are going to get really good at capturing large amounts of information about domains like language and vision.
The number of AI applications is really starting to take off and keeping pace is a good idea
If we can crack the nut of enabling a wider workforce to build AI solutions, we can start to realize the promise of data science. Transferring knowledge between data scientists and data experts (in both directions) is critical and may soon lend itself to a new view of citizen data science.
Before we dive in, I want to make an observation that weaves its way through each of these themes. Transfer learning entails more than just sharing pre-trained models. Transferring trained model pipelines to production is critical, and transferring knowledge between analytical and data experts is a prerequisite to scale. Leaders especially can benefit from an understanding of each aspect of this broader definition of transfer learning.
Deep Learning Trends from GTC21
The Evolution of Deep Learning APIs
Practitioners take heart. Transfer learning, feature sharing, and model deployment may soon be made easier thanks to your favorite deep learning API.
Talk Summary - François Chollet - Keras and TensorFlow: The Next Five Years

François Chollet, an engineer with Google and the primary author and maintainer of Keras, the popular deep learning language that is a high-level API for TensorFlow, feels that we are in the early days of the deep learning era. “Deep learning has only realized a small fraction of its potential so far. The full actualization of deep learning will be a multi-decade transformation.” François sees deep learning applications becoming as commonplace as web development is today. He went on to talk about where Keras is now and what he sees for its future.
He holds the mission of Keras to be the UX that facilitates speed of iterations - from idea to experiment as fast as possible. Keras is optimized for idea expression. The key design principle that Keras enforces is, “progressive disclosure of complexity.” This allows it to achieve good productivity across diverse profiles as different as “a first-year grad student and a Kaggle Grand Master”.
What will Keras look like over the next 5 years? In order to answer that, the Keras team is tracking trends in data science. François sees four trends that he thinks are important and are already driving the Keras roadmap. The first is the emergence of an ecosystem of reusable parts. Pretrained models and feature reuse, for example. Second, he sees a trend toward more automation and higher-level workflows. This takes shape in tuning models by hand but should be automated. The third trend is a trend towards faster, specialized chips for high performance computing, and, yes, this trend is happening in the cloud. The last trend is an increase in the surface area of deep learning applications. François feels deep learning is only solving about 10% - 15% of the problems it will eventually solve.
François’ Trends and the Keras Roadmap
Reusable domain-specific functionality → KerasCV, KerasNLP (import libraries to provide reusable building blocks for computer vision and NLP pipelines), and Keras Applications (larger banks of pre-trained models) are actively being developed.
Increasing automation → Hyperparameter tuning, architecture search, feature banks & lifelong learning, and AutoML are keys to automating what humans will not be doing 5 years from now. The diagram below captures this vision. The algorithm itself will be white box and will have a dialog with the user to make the problem more solvable for the search process. This is ambitious and will not happen in a single release but rather layer by layer. An important part of these foundational layers is Keras Tuner and AutoKeras.
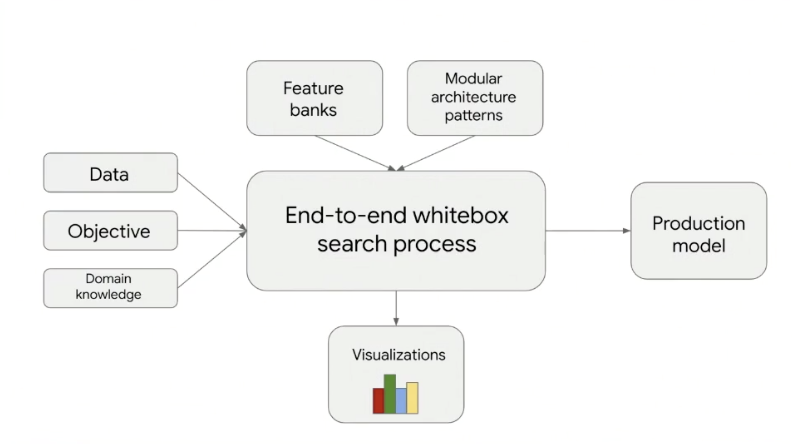
Image from the GTC presentation
Scale & cloud → In the future it will be as easy to train on hundreds of GPUs as it is to train on a Jupyter notebook in a managed workspace. Keras has a new API called TensorFlow Cloud, but this API is specific to GCP.
Into the real world → We will see more mobile, browser, and embedded devices with resource-efficient models and on-device training with privacy and security. This is facilitated, in part, by Keras Preprocessing Layers. Preprocessing should be done in the model. We need to avoid recreating pipelines in JavaScript and training service queues. Your Keras models will now be “raw data in and predictions out” which makes them fully portable.
The Neural Network Architecture Race
So you finally have a handle on CNNs, RNNs, LSTMs, and Transformers. Congrats, you’re officially behind the times. Kidding aside, given the pace of innovation, we all know these amazing, recently curated architectures are just the tip of the iceberg. I review two talks that take a peek beneath the waterline.
Talk Summary - Yoshua Bengio, Full Professor at U. Montreal and Scientific Director at Mila - Quebec AI Institute - Human-Inspired Inductive Biases for Causal Reasoning and Out-of-Distribution Generalization
The Turing award winner provided us a glimpse into a promising new approach to solving a problem all of us face - how to get our models to generalize well in the wild. He describes this work as, “a research direction that I envision for the next few years to expand deep learning in a realm where it needs to go to deal with problems of robustness and out of distribution generalization, incorporating ideas from causality inspired by what we observe about the human condition.”
When we deploy a deep net, the data distribution inevitably changes from what we used to design it in the lab which means our model doesn’t generalize well. Dr. Bengio argues that it is important to understand what those changes mean, and he is seeking a new theory and algorithm to deal with those changes. Humans can reuse knowledge to generalize in new settings so Dr. Bengio turned to human thinking for inspiration, namely Daniel Kahneman’s two-system explanation for human decision making. Kahneman’s ideas have inspired much of what we see in today’s analytical systems so this latest application was exciting to learn about.

View Dr. Kahneman’s keynote address at the data science conference, Rev 2, for his first-hand insights on how human systems of thinking affect modern analytics.
Dr. Bengio mimics Kahneman’s System 2 in a deep net with a new architecture that includes priors. These priors represent assumptions about the world that allow humans to generalize quickly. He shows that they can be thought of as counterfactuals, in the causality sense, and are represented with attention mechanisms that his teams introduced several years ago. These are the foundation of transformers which are at the heart of some of the world’s top language models. These new architectures are learned in a supervised manner by optimizing under changed conditions.

Image from https://manceppo.com/
Talk Summary - Geoffrey Hinton, Emeritus Professor at the U. of Toronto, VP and Engineering Fellow at Google, Chief Scientific Adviser at Vector Institute, and fellow Turing award winner with Dr. Bengio - How to Represent Part-Whole Hierarchies in a Neural Network.
Dr. Hinton’s new vision system is called GLOM. It steals from NLP transformers, unsupervised learning of visual representations via agreement, and generative image models. He argues that having multiple different ways of describing the same shape (multiple frames of reference) is common in human thought but is not available in traditional CNNs. If you are familiar with Dr. Hinton’s work on Capsules (which I blogged about recently), it is interesting to note that GLOM is seeking to accomplish the same task, which is to find a way to classify/understand images from a conceptual standpoint - to move beyond the brute force nature of CNNs. CapsNet took the approach of creating embedding classes ahead of time and seeing which the image activated. GLOM builds them dynamically so that each location in the image knows what part/object it is dealing with. (Hinton says CapsNet was “clumsy” and implies he’s moved on. And this, just when I was starting to grasp that approach. Keeping up is hard to do in data science.) Much like transformers use words in a sentence to give clues to another word’s meaning by their proximity to it, part-whole components in an object-aware image can give the network critical insight into what is happening in the image as a whole. It may also help with model interpretability.
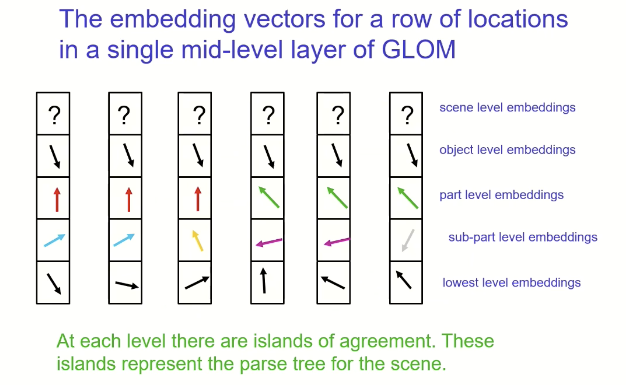
Image from the GTC presentation
The training of GLOM will feel a lot like training BERT, and the hope is that it will lead to models that can lend themselves better to transfer learning for computer vision.
A Burst of New AI Applications
Examples could be found across the spectrum at GTC21, from fraud and anomaly detection to robotics. Across all industries, examples of AI in production abounded. I particularly enjoyed two application talks. In full disclosure, I paid close attention to them as they were given by Dominio customers, but the takeaways are valuable and vendor-agnostic.
Talk Summary - Andrew Modjeski - Lockheed Martin Quality Technologies AI Applications Lead - Keeping the F-35 Flying - An AI Pipeline to Support Quality 4.0
We hear a lot about citizen data scientists lately. We are told that they are the key to federating data science across the enterprise. That’s never set well with me as I can’t imagine enterprises betting their business on models created by less-trained individuals using drag-and-drop tools. In his talk, Andrew Modjeski, shared the way he and Lockheed Martin view the citizen data scientist. The way they explained it made sense to me and bridged the gap I held in my mind.
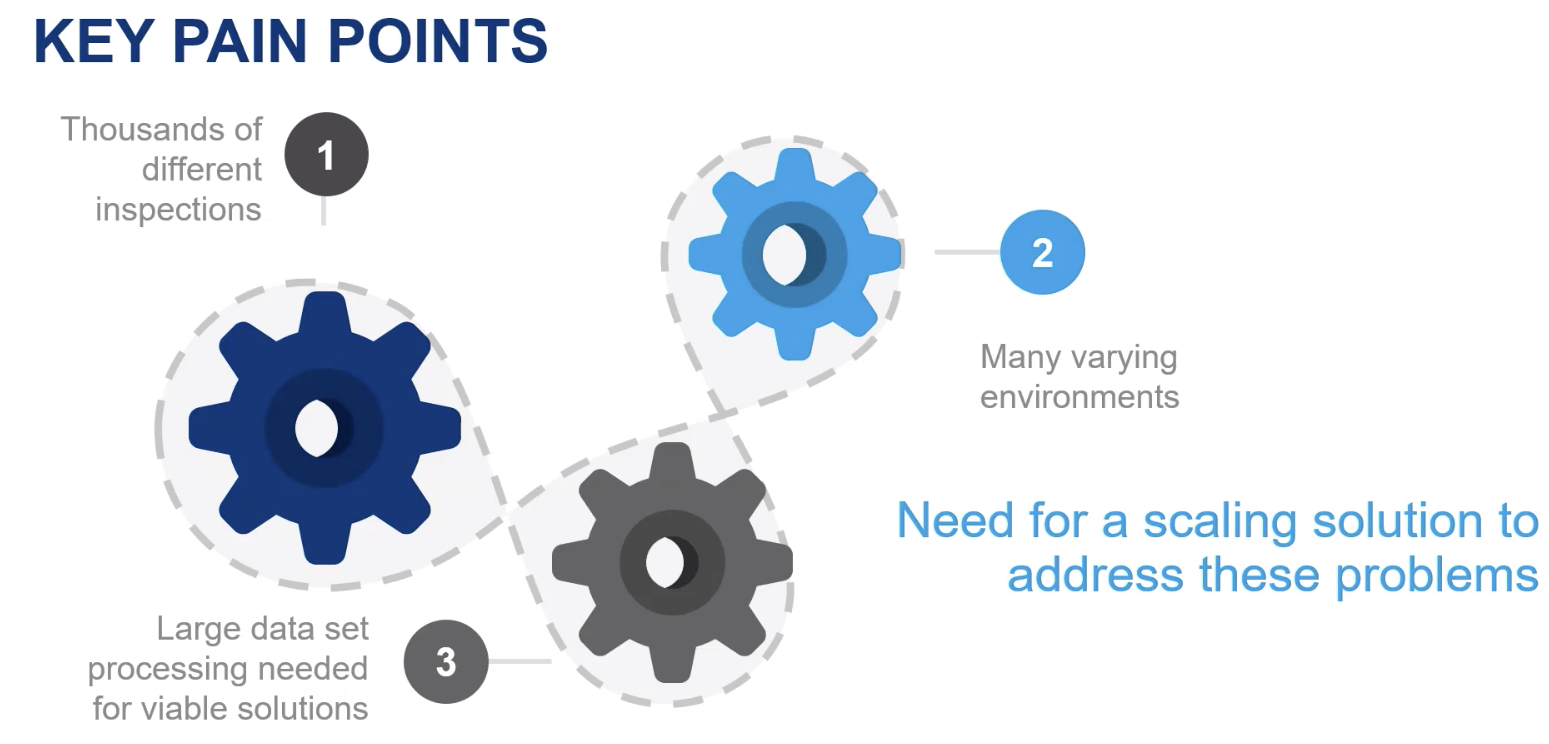
Image from the GTC presentation
Andrew explained, “At Lockheed Martin, the citizen data scientist is our Quality Engineer. It is our Manufacturing Engineer or our Sustainment Engineer. Those are the people who have access to a knowledge of the data… So our goal is to enable those engineers to do AI solutions. The major constraint in doing that is many of those engineers don’t come in with a computer science background… However, what they do come into Lockheed with is a pretty in depth understanding of Matlab... So that is why our focus has been putting Matlab into Domino Data Labs… we need the Domino Data Lab high performance compute to offload that work to the cloud. Additionally, ... we need an easy ability to share data, systematic storage, and project jump-starts, or seedling projects, that a citizen data scientist can base a new solution off of. So, for example, if we create an AI for inspecting fasteners on an F-35 and then we move over to say a C-130 or even rotorcraft, a Sikorsky helicopter, and they want to do an AI inspection of fasteners, they can use our Domino solution as a baseline to start from, and because, at the end of the day they are both fasteners, a similar architecture might work for both projects without many changes. This Domino instantiation allows us to scale these models across the Lockheed Martin enterprise and have citizen data scientists sharing with other citizen data scientists.”
So at Lockheed, citizen data science looks like good old fashioned transfer learning combined with collaborative tools that abstract away the complexities of DevOps in the cloud. Build prototypes with professional data scientists, then engage data experts and enable collaboration so they gain the skills of Jr. data scientists. That’s a citizen data science approach I can trust.
Talk Summary - Sean Otto, Director of Analytics at AES - How AES Went from Zero to 50 Deployed Models in Two Years
In his talk, Sean Otto shared a story that captures what I am seeing across the industry - an explosion of AI & ML applications. Sean explained that “AES is the 5th largest producer of renewable energy globally outside of China. Over 70% of what we generate is renewable.” And the applications at AES are quite diverse, a sign that AI & ML are gaining traction across organizations within model-driven companies.

Image from the GTC presentation
To emphasize this point, let’s look at the variety of applications across AES.
Predictive Maintenance in Power Generation
AES has health reliability indices for their wind farms in a dashboard GUI that updates daily. Reliability engineers use it to know where to start to be more efficient. When you have 75 turbines to deal with, a pointer really helps. In addition to wind farms, AES has over 200 solar plants. Some are in snowy areas. A model called the “snow detection model” is used to determine if energy output variances might be due to snow on the panels.
Hydrology Power Optimization
AES used AI & ML to answer critical business questions around power production. What are inflows expected to bring and how does that compare to similar plants? How do we effectively dispatch in real time and project a day ahead?
Power Grid Infrastructure Threats
When you have a million smart meters, you have to turn some over everyday, much like you would hardware in a large data center. Outage forecasting becomes a must-have. Time to restoration of service is also an important metric to estimate with AI & ML.
Logistics
AES leverages optimization and forecast models. They’ve deployed a stochastic model to identify when fuels should arrive throughout the year and how that affects forecasted supply and demand.
Summary
Analytical leaders should be aware that the pace of models in production is picking up. They can watch the two talks referenced here for some inside baseball on how this is happening. They can also go to the Domino customer stories page for even more sources of inspiration and competitive anxiety. A key takeaway for leaders is that enabling knowledge transfer between employees and organizations is a key to scaling your data science initiatives. Citizen data science should look more like upskilling data experts to Jr Data Scientists than giving them black-box, drag-and-drop AI tools.
Keras and other deep learning APIs are moving in the direction of automation and abstraction of model and pipeline components which will make transfer learning and model deploying much easier in the future. This will also facilitate collaboration and knowledge sharing between humans building AI solutions.
Everyone should be, and probably is already painfully, aware of the fact that nothing is constant in data science except for change. New deep net architectures created/modified in the last 5 years have opened up a new world of solutions. All signs point to that trend of architecture creation continuing. The two interesting talks reviewed here point to a future world where large, broad models capture immense amounts of information about the problem we’re trying to solve. This means there will be a lot of transfer learning and training of the final layers of deep nets with these pre-trained mega-models as the engine under the hood.
All three themes have a thread of transfer learning weaving through them, making me suspect that capturing and sharing knowledge is going to be a key to analytical success in this decade for individuals, teams, and enterprises.

Josh Poduska is the Chief Field Data Scientist at Domino Data Lab and has 20+ years of experience in analytics. Josh has built data science solutions across domains including manufacturing, public sector, and retail. Josh has also managed teams and led data science strategy at multiple companies, and he currently manages Domino’s Field Data Science team. Josh has a Masters in Applied Statistics from Cornell University. You can connect with Josh at https://www.linkedin.com/in/joshpoduska/
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.