
We pit newcomer R data I/O package, feather, against popular packages data.table, readr, and the venerable saveRDS/writeRDS functions from base R. While feather fared well, it did face stiff competition.
They say no good deed goes unpunished. There are few deeds as noble and good as releasing an open source package into a community. You take your hard-fought lessons-as-code, package them up, and release them to be (hopefully) used and expanded. But almost certainly, you will be mercilessly criticized by internet randos (such as myself) with seemingly nothing better to do than to nitpick.
Thus, we find ourselves here: With a shootout of R data I/O packages! We will compare the read and write performance of feather, data.table, readr, and the venerable saveRDS/writeRDS functions from base R.
feather is announced with much fanfare
On March 29th, two of the data science world's most well-known personalities, R's Hadley Wickham and Python's Wes McKinney released to the world "feather". From their announcement:
What is feather?
Feather is a fast, lightweight, and easy-to-use binary file format for storing data frames. It has a few specific design goals:
- Lightweight, minimal API: make pushing data frames in and out of memory as simple as possible
- Language agnostic: Feather files are the same whether written by Python or R code. Other languages can read and write Feather files, too.
- High read and write performance. When possible, Feather operations should be bound by local disk performance.
And our other contenders:
What is data.table?
data.table is an R package that provides an enhanced version of data.frame that allows for fast data manipulations. For the purposes of this benchmark we will be loading all data via the fread function (which a number of benchmarks have shown to be the fastest way to ingest CSV files). We will then be testing out the new fwrite function, which has been added recently (not yet on CRAN), and provides multi-core high-performance disk IO.
What is readr?
readr is an R package that is part of the [Hadleyverse]. It provides a fast and friendly way to read tabular data into R. It provides lots of nice functionality similar to data.table's fread (it guesses column types, stringsAsFactors=FALSE, etc...)
The experimental setup for our shootout
I used the Kaggle Datasets below, and did the following with each of them:
- Loaded the dataset using
fread, with elapsed time noted asread_time. - Wrote it out as a CSV using
fwrite,write_csv,write_feather,saveRDS, and captured elapsed time. - Loaded it as a
featherandRDSfile and captured elapsed time.
We ran each operation 10 times and used the median number in our comparison. For the experiment saveRDS compression was turned off in order to compare apples to apples.
- Lending Club Data from
- Death in the United States from https://www.kaggle.com/cdc/mortality
- College Scorecard from https://www.kaggle.com/kaggle/college-scorecard
- US Consumer Finance Complaints from
https://www.kaggle.com/kaggle/us-consumer-finance-complaints - Earth Surface Temperature Data from https://www.kaggle.com/berkeleyearth/climate-change-earth-surface-temperature-data
- Amazon Fine Foods reviews from https://www.kaggle.com/snap/amazon-fine-food-reviews
Hardware
This benchmark was run on a Domino XX-Large instance with 32 cores and 60GB of RAM. This maps to an AWS c3.8xlarge instance. Reading and writing happened to and from SSD-backed EBS. While the instance we used was not EBS Optimized (with guaranteed bandwidth and latency), the number of iterations run for each operation mitigated against some variance in connectivity to the EBS.
The results
Right off the bat, we're going to say goodbye to one of our favorite competitors. It's pretty clear from the data that readr and its write_csv call are by far the slowest. So, even though Hadley's a super cool guy and I look up to him quite a bit, we're going to go ahead call it the weakest of this benchmark for writing out data. We will be excluding write_csv from all future analysis. Sorry Hadley! I still think you're the bee's knees.

The DeathRecords Dataset
The DeathRecords.csv dataset is composed of 2.6 million rows, with 38 columns, and is 251 megabytes on disk. The dataset is 32 numeric columns and 6 character columns and has zero NA values.
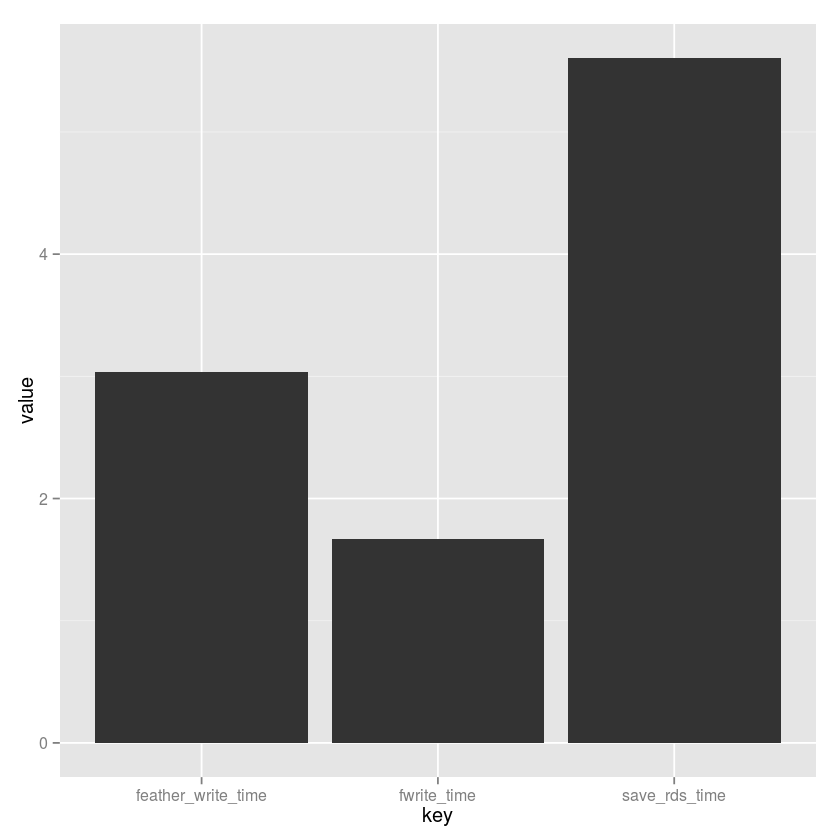
For writing, fwrite is the performance winner at 1.7 seconds, or ~2 times faster than the next fastest, which is feather.
DeathRecords.csv | fwrite_time | 1.666 |
|---|---|---|
DeathRecords.csv | save_rds_time | 5.6035 |
DeathRecords.csv | feather_write_time | 3.035 |
For reading, similar to the other datasets, feather is by far the fastest way to ingest data. As you will see, feather isn't always the fastest way to write out data, but it sure as heck seems to be the fastest way to retrieve it.
DeathRecords.csv | read_time | 5.774 |
|---|---|---|
DeathRecords.csv | feather_read_time | 0.586 |
DeathRecords.csv | read_rds_time | 3.43 |

Global Land and Temperature Dataset
The GlobalLandTemperaturesByCity.csv dataset is 8.5 million rows, with 7 columns, and is 508 megabytes on disk. This file is a mix of numeric and character values and has around 700k NA values.
For writing, data.table's fwrite is once more the performance winner, coming in at ~3 seconds, or twice as fast as the next package, feather in this scenario.
GlobalLandTemperaturesByCity.csv | fwrite_time | 3.2295 |
|---|---|---|
GlobalLandTemperaturesByCity.csv | save_rds_time | 11.1285 |
GlobalLandTemperaturesByCity.csv | feather_write_time | 5.71 |

Again, feather is the fastest way to retrieve data. This time by a very large factor. There is no question at this point: Writing files is going to be a tossup between other packages, but reading is definitive, feather takes the cake. The moral seems pretty straightforward: If you're creating a datafile that is to be read multiple times, feather offers significantly better performance over fread and readRDS.
GlobalLandTemperaturesByCity.csv | read_time | 9.973 |
|---|---|---|
GlobalLandTemperaturesByCity.csv | feather_read_time | 1.639 |
GlobalLandTemperaturesByCity.csv | read_rds_time | 8.7695 |

Amazon Food Reviews Dataset
The Reviews.csv is roughly 500k rows, with 10 columns, and is 287 megabytes on disk. This file is a mix of numeric and character values and has almost no NA values.
In this scenario, data.table's fwrite is the performance winner coming in at ~2 seconds.
It is interesting to note that there is almost no difference between all of the solutions: They all completed writing within milliseconds of each other. The variance seen in earlier tests is not apparent here. I would love to understand why this is.
Reviews.csv | fwrite_time | 1.993 |
|---|---|---|
Reviews.csv | save_rds_time | 2.503 |
Reviews.csv | feather_write_time | 2.249 |

The College Scorecard Dataset
The largest dataset, Scorecard.csv, is roughly 125k rows, with 1,731 columns, and 1.2GB on disk. This file is a mix of numeric and character values and has almost 20 million NA values. In this scenario, fwrite is the performance winner coming in at ~10 seconds. There is quite a bit of variance here, with feather taking nearly twice as long.
Scorecard.csv | fwrite_time | 9.7835 |
|---|---|---|
Scorecard.csv | save_rds_time | 39.3755 |
Scorecard.csv | feather_write_time | 16.527 |

The Consumer Complaints Dataset
The consumer_complaints.csv dataset has roughly 500k rows, with 18 columns, and is 167 megabytes on disk. This file is almost completely character values with a single numeric value, and has zero NA values.
In this write scenario, fwrite is the performance winner coming in at ~1 second. There is some variance here, with saveRDS taking nearly three times as long. feather is approximately 40% slower than fwrite. If this file was going to be read frequently, with such a small delta, feather might provide downstream advantages as an on-disk format.
consumer_complaints.csv | fwrite_time | 1.1455 |
|---|---|---|
consumer_complaints.csv | save_rds_time | 2.68 |
consumer_complaints.csv | feather_write_time | 1.417 |

Loan Data
The loan.csv dataset is roughly 880k rows, with 74 columns, and 421 megabytes on disk. This file is a mix of character values with a 2 to 1 ratio for numeric value and has very high percentage of NA values (nearly 15 million.) In this scenario, fwrite is the performance winner coming in at ~2.8 seconds, both with and without turbo enabled. Unlike with the College Scorecard dataset, saveRDS achieved better results here. It appears that with increasing sparsity (high density of NA values) saveRDS performs better.
loan.csv | fwrite_time | 2.905 |
|---|---|---|
loan.csv | save_rds_time | 7.998 |
loan.csv | feather_write_time | 5.043 |

The Takeaway
The two big takeaways I have from this experiment are:
- For the purposes of ingesting datasets, it's going to be really hard to beat
feather. It's just incredibly fast. Much faster than anything else I was able to benchmark. - Both
featherandfwriteoffer great writing performance of tabular files. As a rule, if you have a box of similar configuration to our experiment (lots of cores and RAM, and SSD disks),fwriteseems hard to beat for writing. One or two ingests of that file though, and you may wish you hadfeathered it.
As with all benchmarks, this benchmark is limited and incomplete. We ran the experiment on one machine with one configuration. Dataset sparsity also appears to have some influence on results and we did not test explicitly for variances in sparsity. Your mileage may vary: You may see completely different performance characteristics on your system and dataset.
What I can say beyond a shadow of a doubt is that readr is not particularly fast at writing files. If you're still using write.csv or similar, you're wasting a lot of electricity!
Finally, a few other package idiosyncrasies to note:
- Only one of these tools offers cross-language support (putting CSV-aside). If you want to easily and quickly share complex data between Python and R apps, you really only have one choice:
feather. saveRDS/readRDSandfeatheruse a binary format, rather than the CSV text format. Binary has downsides: You can't use familiar and long-standing command line tools like head, tail, wc, grep and sed. A binary format is also opaque, with the possibility of breakage and backward incompatibility as the package develops and the format changes.
Summary Statistics
In the chart below we see that for the average case feather and fwrite seem to perform very similarly. For the worst case, fwrite is faster than the average case for saveRDS.

feather_write_time | 1.417 | 5.6635 | 16.527 |
|---|---|---|---|
fwrite_time | 1.1455 | 3.45375 | 9.7835 |
save_rds_time | 2.503 | 11.54808 | 39.3755 |
From the above, feather and fwrite are very much the winners. feather does, however, have a considerably worse "worst case" behavior for writing. How you amortize the savings on feather's read operations is an exercise left to the reader.
Final Thoughts
Benchmarks can be contentious. I hope this one is not super-so! The code and data is all available in the Domino project linked to above. I welcome suggestions (and code) for improving the experiment. A big thank you to Matt Dowle and Arun Srinivasan for their great work on data.table, and to Hadley Wickham and Wes McKinney for their awesome work on feather! The world of getting data in and out of analytical environments has taken a pretty great leap forward in 2016, and we're lucky to be able to reap the benefits!

Eduardo Ariño de la Rubia is a lifelong technologist with a passion for data science who thrives on effectively communicating data-driven insights throughout an organization. A student of negotiation, conflict resolution, and peace building, Ed is focused on building tools that help humans work with humans to create insights for humans.
RELATED TAGS
SHARE



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.