What is the Data Science Lifecycle for Data Science Projects?
David Weedmark2021-08-06 | 12 min read

Data science is an incredibly complex field. When you factor in the requirements of a business-critical machine learning model in a working enterprise environment, the old cat-herding meme won’t even get a smile.
Framing data science projects within the four steps of the data science lifecycle (DSLC) makes it much easier to manage limited resources and control timelines, while ensuring projects meet or exceed the business requirements they were designed for.
What is the Data Science Lifecycle?
The data science lifecycle (DSLC) is a series of iterative steps to create, deploy and monitor an analytical model. At its highest level, the data science lifecycle (DSLC) consists of four phases: Manage, Develop, Deploy, and Monitor. Within each phase there are multiple iterative steps through which a project progresses to ultimately generate a production model. The project may loop back through prior steps to get more data, build new features, try a different algorithm, adjust hyperparameters, and so on. Even after deployment, when model performance decays a model will return to a prior step to be retrained or rebuilt.
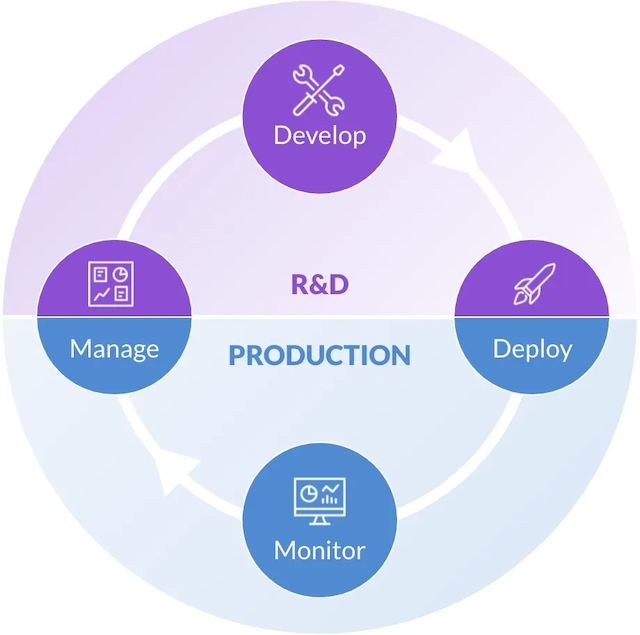
What are the 4 Steps in the Data Science Lifecycle?
The data science lifecycle categorizes all of the tasks within any given project within four broad steps. This not only helps in creating a bird’s eye view of each project as a whole, it makes it easier and more efficient in determining where resources will be required, and for identifying how each project is progressing. The four steps are:
- Manage: Multiple people and teams are involved in the various steps including IT operations, business stakeholders, data science leaders, data scientists, data analysts, developers, data science product managers, ML engineers, and data engineers.
- Develop: Data is accessed and prepared, then features are created. Multiple models are built, evaluated, and documented. When a final model is selected, it is validated to ensure it solves the business problem and is technically sound.
- Deploy: Models are registered into a central repository and tested to ensure they will perform as expected when in production. All model artifacts are retained and cataloged. They are approved for deployment through model governance processes, and integrated into a system or process for use. Business adoption is assured through change management.
- Monitor:Models are continually monitored for performance and drift, and action taken when performance degrades. Business value realization is captured and communicated
Let’s use an example business problem to illustrate the four steps of the data science lifecycle
The Manage Step
The Manage step should involve a cross-functional team, including representatives from the business unit, data scientists, engineers, analysts and developers. This is where everyone gets together to frame the problem to be solved, come up with the solution approach and then identify and prioritize the project requirements, both from a technical and business perspective.
Identify the Problem
No solution can predate a problem. Suppose a retailer has several thousand products for sale on its website. Determining the best price for each item is primarily done manually by discounting entire categories based on historical trends, as well as by comparing top sellers with competitor pricing. This is an extremely time-consuming and inefficient process that would be much more efficient using an ML model. A critical output of this phase is understanding the decision, or decisions, that will be impacted with the ML model.
Assess the Project
Your business unit wants to use live data from competitors to change prices dynamically, weighted by in-house historical pricing and sales volume. After some discussion, you determine that you will need to create a live database of competitor pricing. Manufacturer SKUs are not always available and retailer SKUs vary with each company, so identifying competitor products will require a model that can incorporate SKUs, product descriptions and images. An existing model from a previous project that compares images and descriptions to gauge product popularity can be repurposed for this project. Some projects may end here, if it is not feasible to obtain the data or resources needed to accomplish the goals.
Prioritize the Project
Not only do the tasks within each project need to be prioritized and roles assigned, but work required on other projects need to be considered as well. In our pricing example, you determine the first course of action will be to develop an API that can pull data from three competitor websites and create a new database. This will keep your data engineer and developer busy for a couple days. In the meantime, your data scientists can finish working on another pressing project that was deployed but needs to be updated.
The Manage phase is both the beginning and the end of the data science lifecycle. An ML model in production may degrade and may need to be retrained and prioritized alongside new requests. In other cases, ML models in production may be used for new projects in order to achieve higher orders of value for the organization.
The Develop Step
For data scientists, the Develop phase is where all the fun begins. There are usually three components to development, beginning with accessing the data, exploring and preparing that data and then researching and developing the model.
Access Data
In our pricing model example, much of the data needs to be pulled from the internet and put into a new database. Historical inhouse data should already be available, but it needs to be made accessible. In other situations, however, the data may not be available and has to be purchased from another source.
Explore and Prepare Data
In most cases, the data needs to be prepared for . Missing data needs to be addressed, data needs to be categorized, extraneous data and duplicate columns need to be removed, and only data that is available during the time of prediction may be used. For example, you can’t use temperature when predicting the energy demand as you only know actual temperature after the fact. In this case, you would have to use predicted temperature. Incorrectly preparing the data can be just as important as actually building the ML model.
Research and Development
During this part of development, data scientists begin creating models and conducting experiments to test their performance. There is a lot of trial and error in this part of development, as different algorithms are assessed and modified as needed. Oftentimes, you will need to go back and prepare the data again, as changes in the models being tested can require different variables.
The end result of R&D should be a working model, incorporating the features identified in the Manage step, that performs as required
The Deploy Step
The Deploy phase is where the tested model is transferred to a production environment. Ideally, this is where the project is handed off from the data scientists to the developers and engineers, although oversight by a lead data scientist is often required from the beginning to the completion of the project.
Validate your model
The tested model is analyzed and validated according to corporate governance, laws or the requirements of certifying bodies. This ensures the model has been built properly, ethically and without bias. It also ensures that the model is not misusing data to achieve its results. This is of primary importance in healthcare and finance, for example. As well, any company that collects data will have to abide by both the law and its own user agreements on what can and cannot be done with customer information.
Publish your model
The working model is put into its production state and analyzed. In our pricing model example, the model would be given access to data on the client’s servers and a working version of the database collecting live data from competitor websites. If it encounters any problems, or if it isn’t working as predicted, the model may need to be terminated and a new series of tests conducted, bringing the project back to the Develop step.
Deliver your model
Once the working model has been successfully published, it can be delivered to the business units that will be using it. The Deliver phase includes incorporating the model into a business process, training users, and ensuring that the model is used as planned. In our pricing model example, an API would be added so that it can be monitored and any changes it makes to the prices of products can be reviewed in real-time.
The Monitor Step
Sending an ML model out into the business world is never the end of the data science lifecycle. Monitoring is a fundamental part of the process.
First, the incoming data needs to be monitored. In our pricing model example, inhouse data should be relatively stable and if any changes are to be made, those overseeing the ML model should be notified in advance. This isn’t the case for other sources of live data, which can change at any time without notification. Model monitoring is required to ensure that the team is notified of any changes to the input data, regardless of the source - as the model may need to be redeveloped.
Secondly, the model needs to be monitored to ensure it consistently delivers the value required from a business perspective. In our pricing model example, product costs or a minimum markup should have been factored into the model. Otherwise, the model could easily start to mark products below cost, which could become a serious problem for the company’s bottom line.
Thirdly, not only do you need to monitor the model and its data sources, the end users should also be monitored, especially in the early days of adoption. You’ll need to ensure that they can access the results they need and that the information being provided to them by the model is usable. This usually involves training, but in some cases modification to the platform or the user interface may be required.
Regardless of how well the working model performs, once it is performing as predicted and users are comfortable integrating it into their own workflows, the team should meet again to determine if the same, or a similar model, can be used in other environments.
Using Enterprise MLOps to Drive DSLC Adoption
Adopting the data science lifecycle into your company’s data science projects is much easier when you have the tools and frameworks already in place. Domino’s Enterprise MLOps Platform was built from the ground up with DLSC-based collaboration in mind, so that every business requirement, every resource, every dataset, algorithm and experiment is documented and sourceable within the same platform.


David Weedmark is a published author who has worked as a project manager, software developer and as a network security consultant.
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.