
At Data By The Bay in May, we saw a great talk by Netflix's Justin Basilico: Recommendations for Building Machine Learning Software. Justin describes some principles for effectively developing machine learning algorithms and integrating them into software products.
We found ourselves nodding violently in agreement, and we wanted to recapitulate a few of his points that resonated most strongly with us, based on our experience working with data science teams in other organizations.
Machine learning is iterative (slides 15-17)

Justin emphasizes that "developing models is iterative" and experimentation is important. He also suggests "avoiding dual implementations" so it's easy to use a model in production once it's been built, without a re-implementation step.
Domino enables experimentation and productionization in the same platform, so you can iteratively develop your models and deploy them with one click — without worrying about translating your code or configuring a matching set of packages on different infrastructures.
We have two short videos highlighting how Domino enables rapid iterative experimentation and lets you deploy models as APIs to avoid dual implementation.
Maximize a single machine before distributing your algorithm (slide 26)

Justin suggests avoiding the "temptation to go distributed" and doing as much as you can on a single machine. Distributed systems are hard — more difficult to set up and use, and less reliable! We couldn't agree more. By all means, go distributed if you really need to given the scale of your data — but don't start there if you can avoid it.
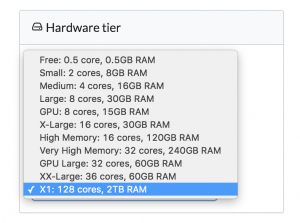
Domino's approach to this is to make it easy to run your analyses on massive single instances. We've always supported AWS instances with 32 cores and 240GB of memory, and as of last week, we support Amazon's new X1 instance, letting you run Jupyter, RStudio, batch scripts, or whatever you want on machines with 128 cores and 2TB of RAM. You can read more here.
Don't just rely on metrics for testing (slide 32)

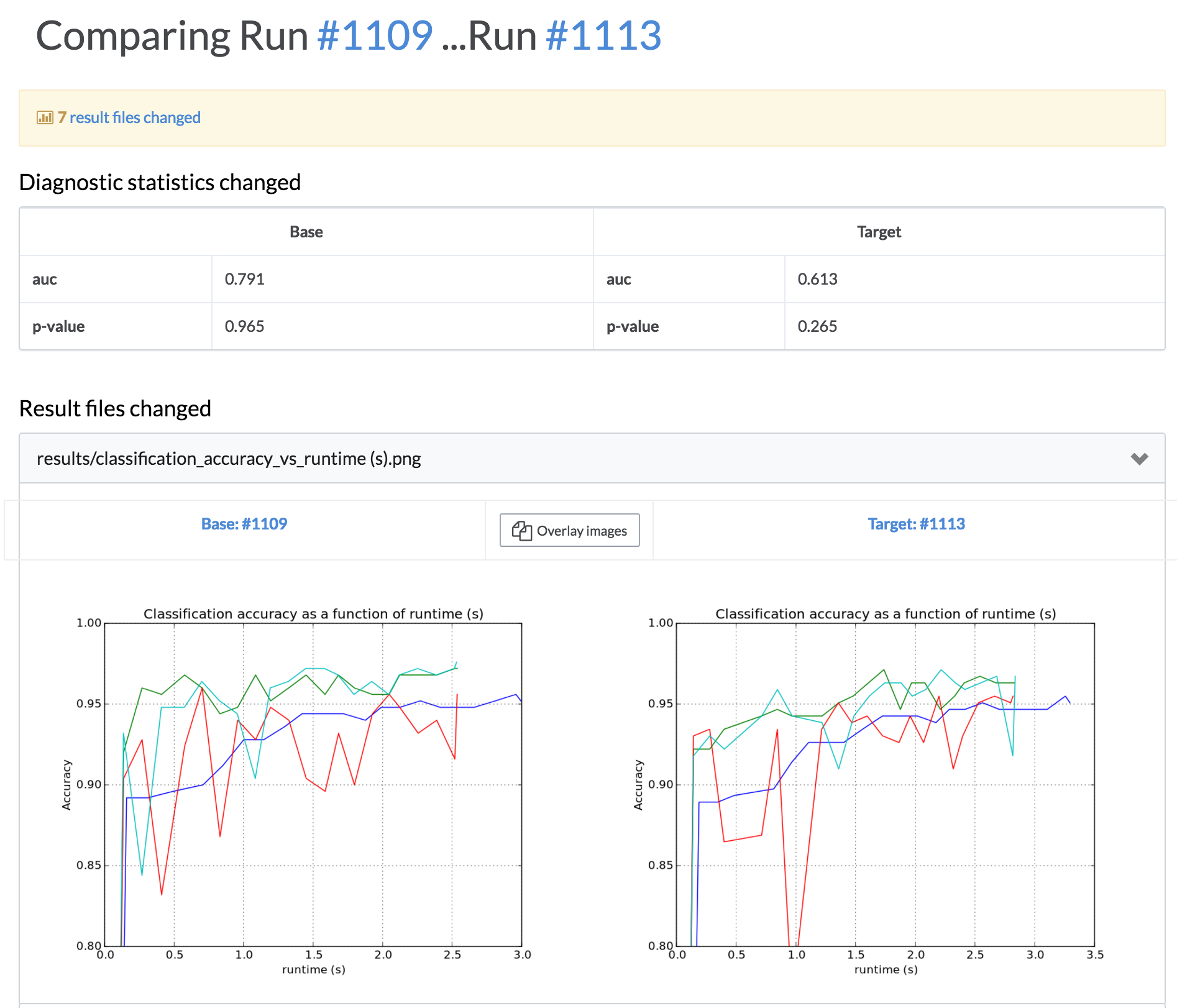
Justin explains that while unit testing is great for catching math errors, it's important to look at outputs of the wholes system and, "at a minimum, compare output for unexpected changes across versions"
We recently wrote about our views on unit testing for data science and how Domino's "comparison" feature facilitates this type of output comparison.
Conclusion

We have built Domino with many of these exact principles in mind. Domino enables rapid iteration and experimentation while making it easy to productionize without a redundant implementation of your model. We do this primarily by letting you scale up to large machines (and use many machines to run multiple experiments simultaneously). We also enable a more holistic testing and comparison process by tracking all experimental results and letting you compare them.
If you enjoy reading about principles and best practices for enabling a more mature data science process, you'll enjoy our posts about What's a Data Science Platform and our "Joel Test" for data science.
Banner image titled “Recursive Daisy” by Nic McPhee. Licensed under CC BY 2.0.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.