spaCy
What is spaCy?
spaCy is a free, open-source Python library that provides advanced capabilities to conduct natural language processing (NLP) on large volumes of text at high speed. It helps you build models and production applications that can underpin document analysis, chatbot capabilities, and all other forms of text analysis.
The two principal authors for spaCy, Matthew Honnibal and Ines Montani, launched the project in 2015. The spaCy framework—along with a growing set of plug-ins and other integrations—provides features for a wide range of natural language tasks. It’s become one of the most widely used natural language libraries in Python for industry use cases, and has quite a large community—and with that, much support for commercialization of research advances as this area continues to evolve rapidly.
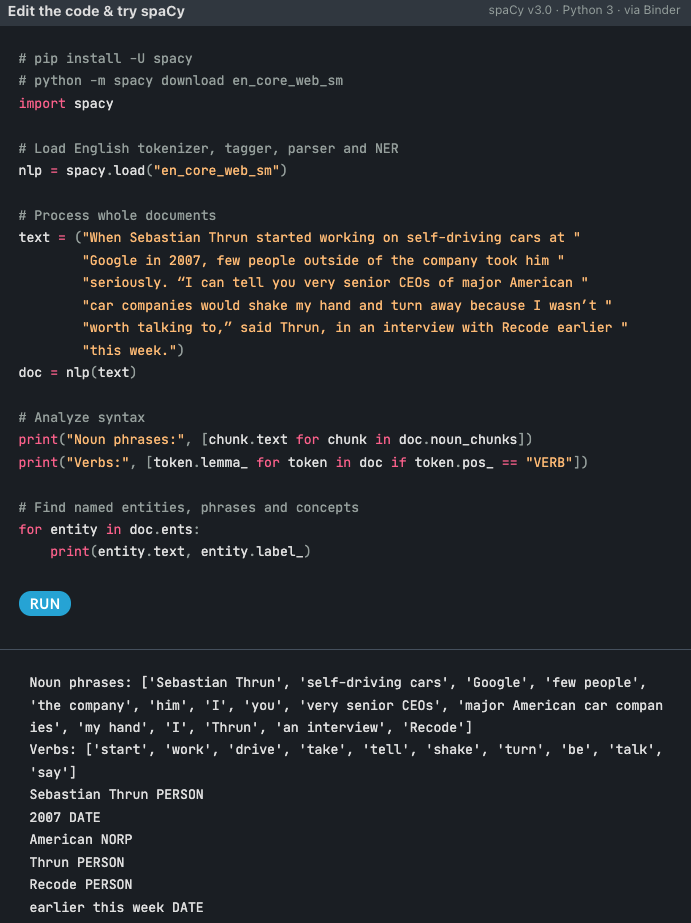
Source: spacy.io
The spaCy Universe offers deep-dives into particular use cases and to see how this field is evolving. Some selections from this “universe” include:
- Blackstone – parsing unstructured legal texts
- Kindred – extracting entities from biomedical texts (e.g., Pharma)
- mordecai – parsing geographic information
- Prodigy – human-in-the-loop annotation for labeling datasets
- Rasa NLU – Rasa integration for chat apps
- spacy-pytorch-transformers to fine-tune (i.e., use transfer learning with) BERT, GPT-2, XLNet, etc.
SpaCy 3.0
The latest release, spaCy 3.0, brings many improvements to help build, configure and maintain NLP models, including:
- Newly trained and retrained transformer-based pipelines that lift accuracy scores significantly
- Additional configuration capabilities to build your training workflow and tune your training runs
- A Quickstart Widget to help build your configuration files
- Easier integration with other tools such as Streamlit, FastAPI, or Ray to build workflows
- Parallel/Distributed capabilities with Ray for faster training cycles
- Wrappers that enable you to bring in other frameworks such as PyTorch and TensorFlow
These features combine to make spaCy better than ever at processing large volumes of text and tuning configurations to match specific use cases in a way that provides better accuracy.