
Generative AI and Large Language Models (LLMs) like OpenAI's GPT series or Meta's Llama2 are revolutionizing our economy. AirBnB and JetBlue already use generative AI (GenAI) to improve customer experience through chatbots. Biopharma company Eli Lilly uses GenAI to discover novel drug compounds. And JP Morgan creates synthetic data with the technology, securing customer privacy for R&D efforts. However, deploying and making inferences using these models presents a unique set of challenges.
LLM Inference and Hosting Challenges
LLMs and their accompanying data are typically large and require considerable amounts of memory. This memory requirement limits the types of hardware capable of running LLMs to the highest-end GPUs. This hardware is in high demand, especially in cloud environments. High demand results in higher prices. Costs can skyrocket if an LLM needs to be online and inferencing constantly. Furthermore, LLM inference can be energy-intensive, particularly on CPUs or GPUs. Optimizations such as knowledge distillation and quantization can reduce model size but may affect model precision.
Domino Gives Enterprises Control Across the LLM Fine-Tuning Lifecycle
Enterprises looking to develop AI quickly, responsibly, and cost-effectively have turned to Domino for years. Businesses are learning rapidly GenAI is different. It requires entirely new skill sets, data at a different scale coming from multiple business units, and robust, high-performance infrastructure. It also requires new risk assessment and mitigation strategies. And operationalizing GenAI models becomes a long-term investment and commitment. As before, Domino now leads the charge, enabling enterprises to harness generative AI without compromising risk, responsibility, and security.
Practitioners use Domino to fine-tune LLMs using the latest optimization techniques. Fine-tuning is an iterative process. Domino simplifies that by managing experimentation with its reproducibility engine. Reproducibility ensures that your model is valid and those great results were not a fluke. It improves trust in the model, mitigating concerns over LLMs’ impact. And if a model audit is necessary - you’re always ready. With Domino’s help, enterprises can release LLMs responsibly.
Moving troves of data between cloud locations or on-prem is expensive, slow, and risky. Domino customers can fine-tune and deploy LLMs co-located with data wherever it is using Domino Nexus. Workload co-location also helps enterprises comply with sovereignty and privacy regulations.
Companies have trouble hosting and scaling traditional AI models, let alone LLMs. Domino can host your models - including LLMs - for inference. You can share your model as a user-friendly web application or set up a model API to help it connect with other systems. And by automating infrastructure provisioning, Domino empowers practitioners to create and deploy models quickly; no DevOps knowledge is needed.
Given the high-end infrastructure LLMs need when put into production, you must keep an eye on operational costs. Domino includes extensive cost monitoring and budgeting tools. It can help you track spending on projects, models, APIs, and more. You can even set spending alerts and limits to ensure budgets are not exceeded.
Enterprises will want to keep an eye on leveraging their LLM investment for future projects. With one successful generative AI model in production, most companies will develop an appetite. To make that easier, Domino offers broad knowledge-sharing and collaboration tools. Other teams across multiple business units can recreate all code, metadata, IDEs, packages, and development environments. This helps accelerate future development and limits the need for expensive reinvention.
Let's look specifically at how Domino makes LLM inference happen.
LLM Inference On Domino: The Reference Project
In a previous post, we shared reference projects highlighting efficient LLM fine-tuning techniques utilizing Domino. Now that the models are 'fine-tuned,' we look into a reference project covering model inference.
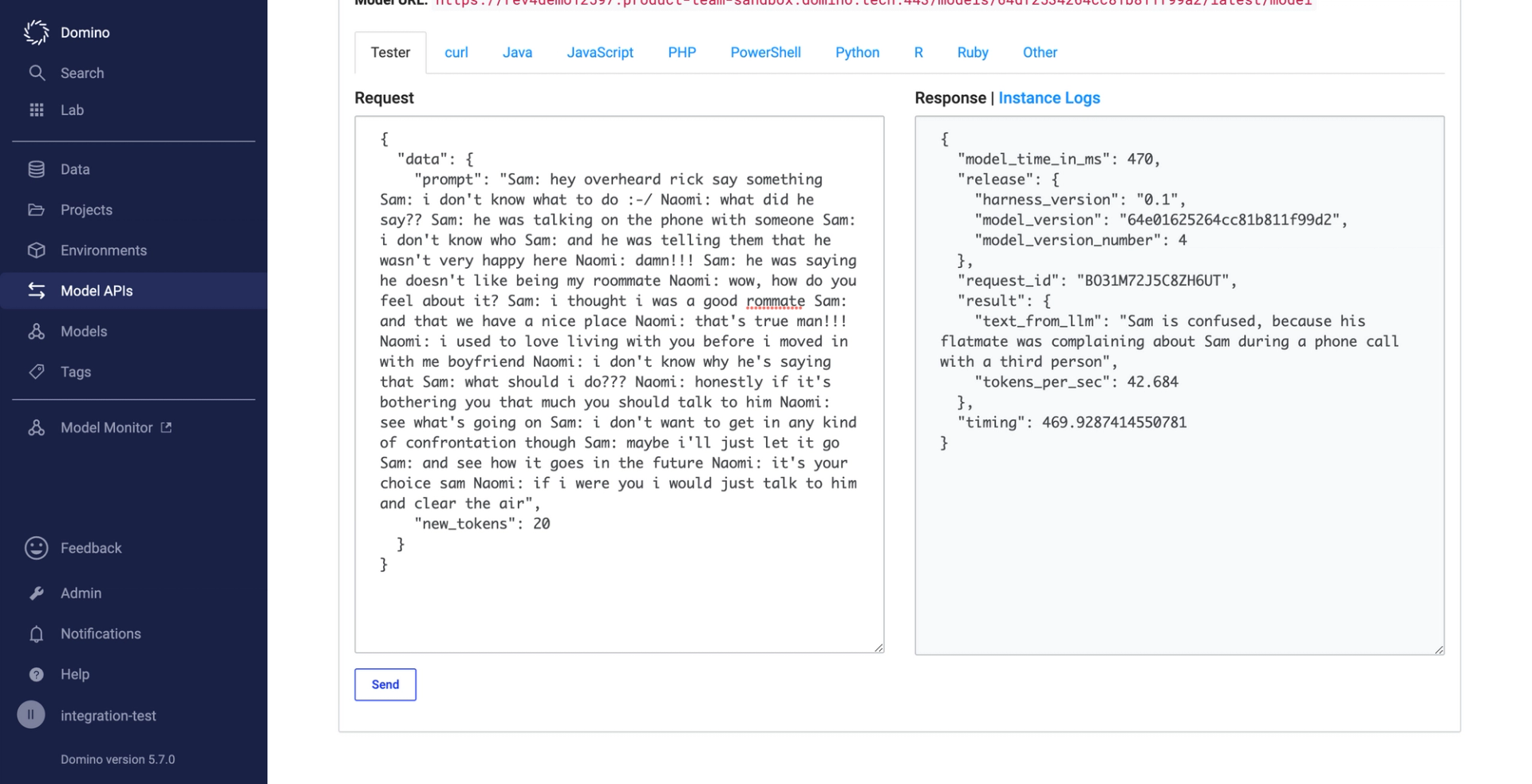
This project demonstrates the generation of text output from a fine-tuned Falcon-7b LLM using multiple inference frameworks. It showcases not just the execution but also provides guidance on Model API and web app deployment in Domino.
From the get-go, we sought to showcase realistic, cost-effective execution. Depending on your choice of hardware and LLM, execution times will vary. For benchmarking, we executed the reference project on an NVIDIA V100 GPU with 24GB of VRAM. Robust, but no longer the peak of innovation.
The Right Inference Framework Matters
An increasingly important element in hosting LLMs is the choice of an inference framework. An inference framework is a set of tools and libraries developed to efficiently deploy, run, and manage LLMs in production environments. The environments aim to reduce memory footprint, accelerate execution and simplify scaling the models to serve a high request load. The frameworks also offer other significant benefits: They minimize model integration complexity with applications or systems and assist in managing different model versions.
The project's goal is to set up and run a chatbot. The LLM will run as a Domino model API. We will also set up a Streamlit app on Domino as the model's user interface.
We tested three inference frameworks on Domino:
- ctranslate2: Historically, ctranslate2 focused on neural machine translation and transformer architectures rather than general LLM tasks. It is, therefore, ideally suited for translation tasks. We also found it ideal for those keen on running LLMs on CPU (x-86-64 and ARM64) or GPU, as it reduces memory footprint and accelerates execution. Ctranslate2 ended up being the fastest framework in our tests.
- vLLM: Developed by researchers at UC Berkeley, vLLM uses transformer-specific techniques to achieve high-performance optimizations. vLLM's integration with Ray Serve makes it ideal for large-scale inference operations.
- Huggingface Transformers: An excellent choice for prototyping, development, and smaller-scale inference projects that leverage GPUs.
Navigating the Repository
To help practitioners looking to tailor the reference project to their requirements, here's a rundown of its critical files:
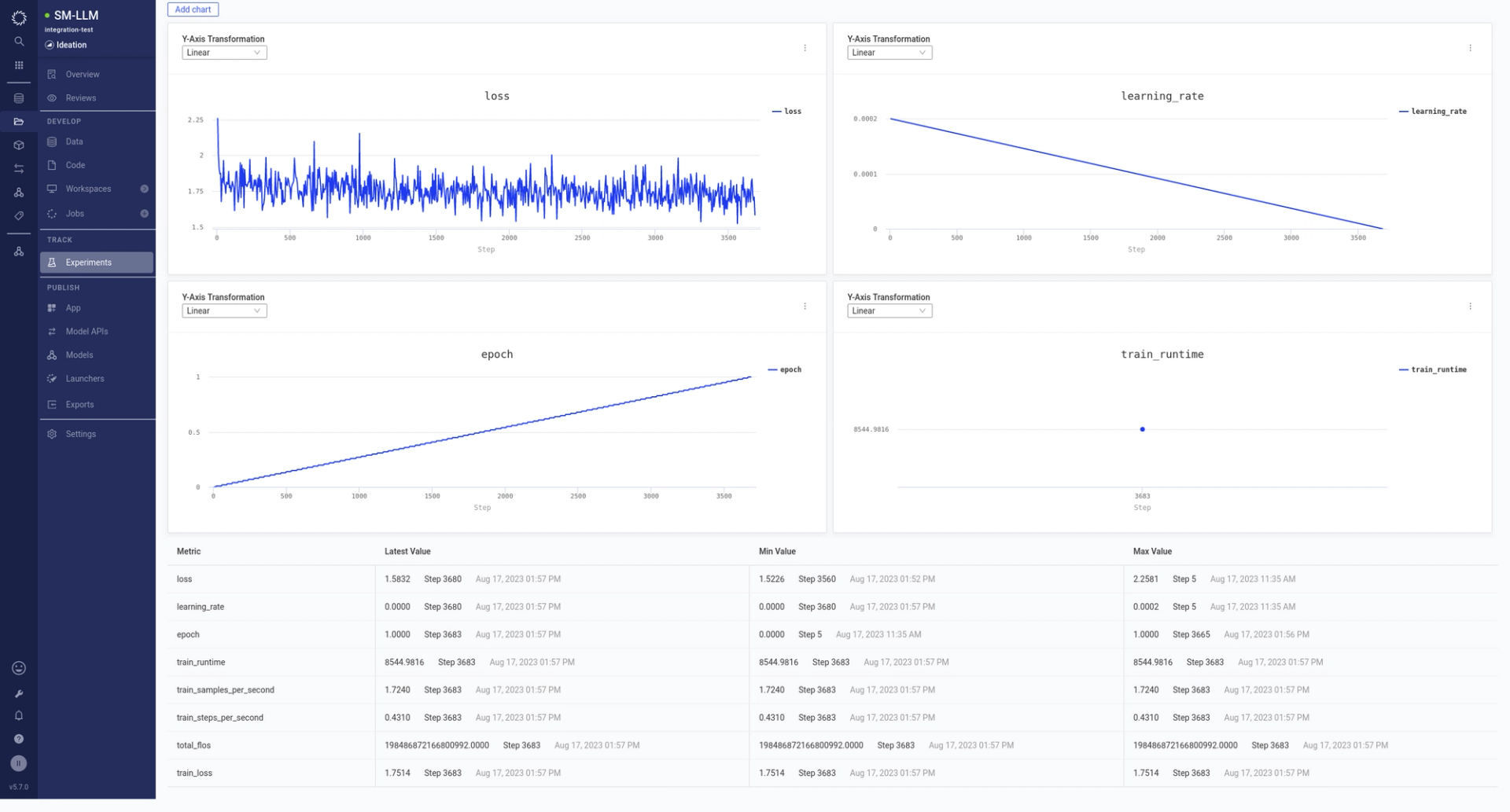
- ft_falcon7b_8bit_lora.ipynb: As the first step, this notebook deals with fine-tuning a LoRA adapter for Falcon-7b to achieve summarization. Bonus? It logs training metrics to MLflow, viewable in the project's Experiments section.
- convert_hf_ct.ipynb: Interested in converting our fine-tuned Falcon-7b model to a ctranslate2 model? Since ctranslate2 does not support adapters, we merge them with the model to overcome this limitation.
- bench_ct2.ipynb: This notebook takes the merged model, loads it as a ctranslate2 model, and uses it to derive output.
- bench_hf.ipynb: This notebook loads a Huggingface-based model and uses it to generate output.
- bench_vllm.ipynb: Harness the power of vLLM with this notebook. It facilitates output generation from a Huggingface model equipped with a summarization adapter.
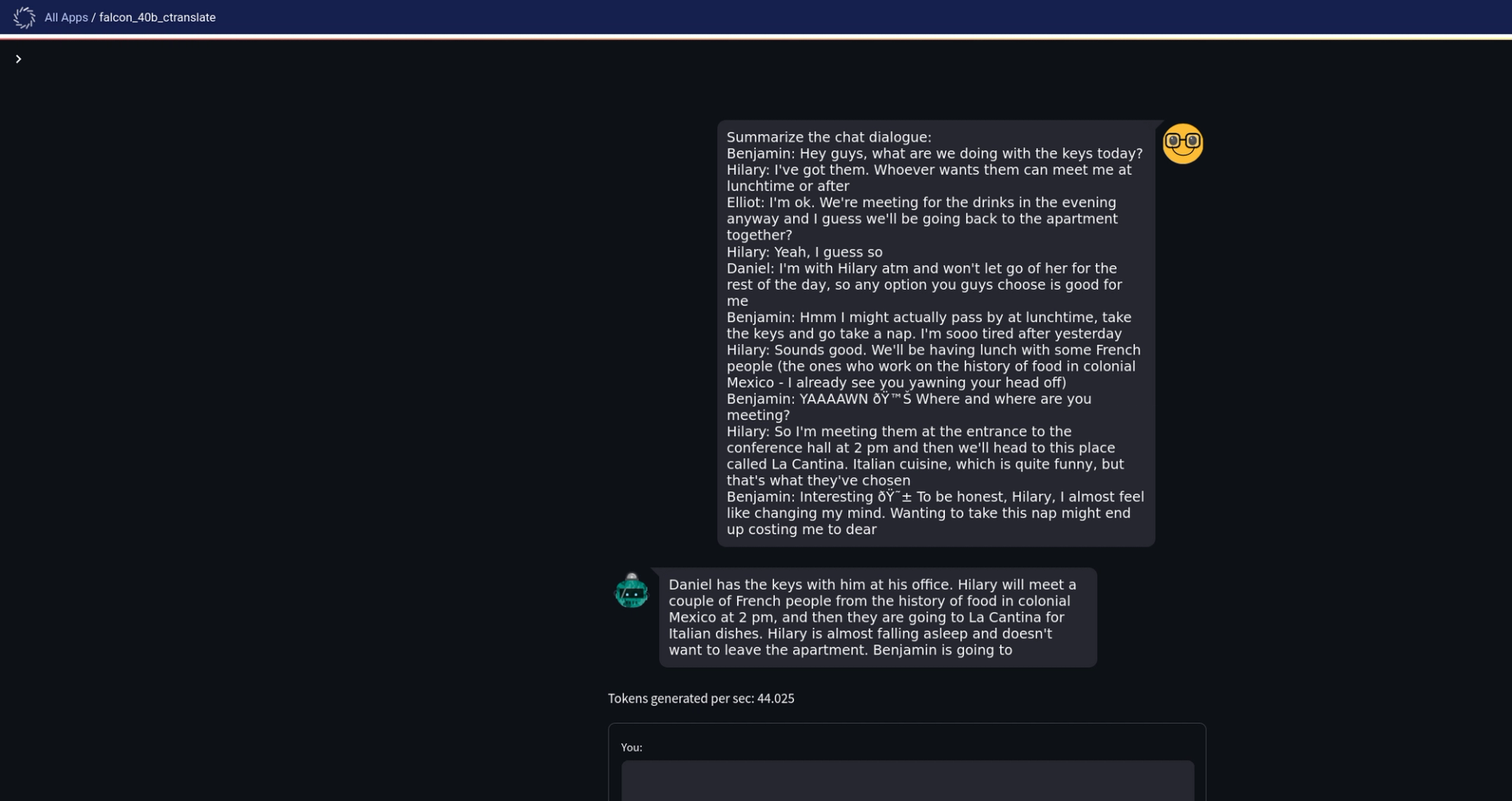
- app.py: A sample Streamlit app offering a user interface for the LLM summarization. It produces responses from the ctranslate2 model.
- app.sh: The startup shell script for the chat application.
- model.py: The file offers a blueprint for using the ctranslate2 model as an API. Since we are still dealing with LLMs, set your Domino build pods up to have sufficient resources to build the API. Also, verify that the Model API has a large resource quota assigned.
Conclusion
Setting up LLM models for inference is a bit of a dark art.
This reference project shows how practitioners can now use Domino to host, scale, and share LLMs. And as before, they do this without slowing down or taxing IT resources. Domino again sheds light on the forefront of AI.
As we have demonstrated, Domino is the best solution for enterprises looking to harness the power of generative AI overall, particularly LLMs.
- With generative AI and LLMs, one-off, artisanal data science is no longer sustainable. You need a platform offering access to the latest open-source innovations as they emerge. Data scientists need to securely access data from multiple sources across the organization. They need powerful and flexible infrastructure with GPUs and cluster technology. Domino provides this broad and open foundation for generative AI.
- As new technologies introduce novel risks, Domino gives you control. It provides enterprises with a governance framework for responsible AI practices that are fast becoming critical in the world of LLMs. Domino tracks development, data, and infrastructure, with experiment reproducibility at its core. It ensures organizational alignment and helps manage model release processes. Domino even helps companies comply with the growing maze of data sovereignty and privacy laws.
- LLMs and generative AI can become expensive experiments. Domino gives you cost controls to ensure teams adhere to budgets and to help keep operational spending in check. It helps you build on and reuse code and experience gained building the models. Both capabilities make building the next model faster, more reliable, responsible, and cost-efficient.
Interested to learn more about how Domino can help you on your generative AI journey or want to see Domino in action? please reach out to us here.

Subir Mansukhani is Staff Software Engineer - 2 at Domino Data Lab. Previously he was the Co-Founder and Chief Data Scientist at Intuition.AI.
Other posts you might be interested in



Data Science Platform
Domino expands Generative AI capabilities with AI Gateway and Vector Data Access
Read MoreSubscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.