Assess Your Data Science Lifecycle
The data science process is more than just a set of instructions to follow in order to make data science projects impactful.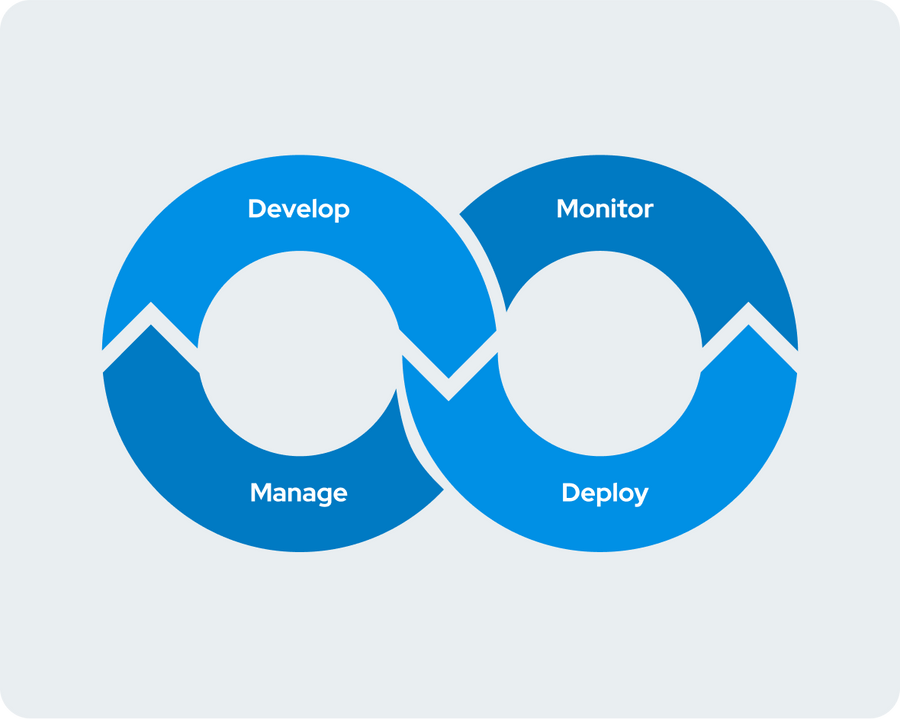
Take a free 10-minute assessment
Broken down, there are four stages to the data science lifecycle that, when invested in and optimized, allow enterprises to achieve the model velocity necessary to become successful model-driven businesses. They easily access the tools and compute for data science projects, onboard new data scientists efficiently, re-use prior work, and rapidly experiment, publish, monitor, and retrain models.
Take this free 10-minute assessment and see where your data science process and lifecycle stacks up towards achieving model velocity, with suggested areas of improvement on the road towards becoming a true model-driven business.
Domino scales data science and its value with a centralized, modern platform that data scientists love and IT administrators trust. The result? Data science is unleashed to deliver transformative value across your organization and to your customers.
Enter your email address to begin.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.
Get your score in minutes
Answer a series of yes or no questions intended to examine where risks and opportunities are within the four stages of the data science lifecycle (Manage, Develop, Deploy, Monitor). After completion, you’ll immediately receive a Model Velocity Assessment with areas of improvement and actionable recommendations.
Take the assessment
Spend less than 10 minutes answering a series of yes or no questions about your data science process and lifecycle.
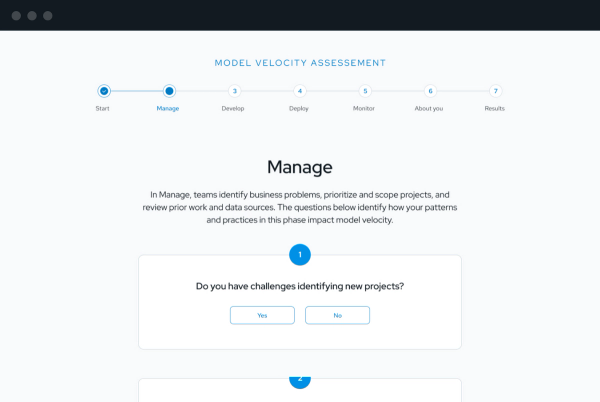
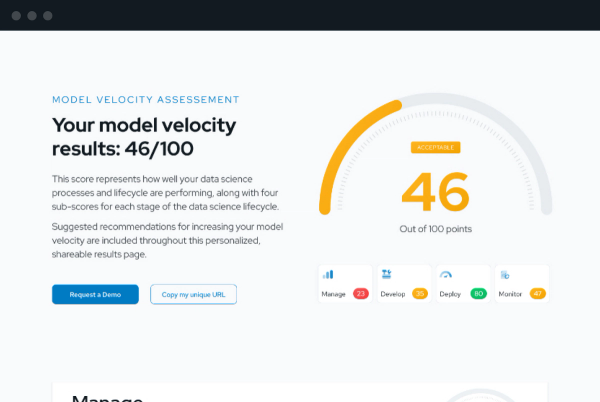
Receive your score
Delivered immediately, your Model Velocity Assessment will give you a detailed, shareable (anonymous) page of results including your overall score and the sub-scores for each lifecycle stage.
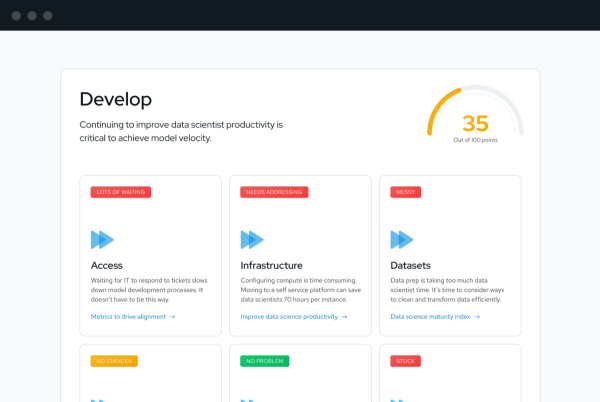
Review personalized tips
Your results include personalized, actionable tips from the experts at Domino so you’ll move forward knowing exactly how and where to maximize your Model Velocity.
Frequently Asked Questions
Will I be able to share my results?
What is model velocity?
What are the phases of the data science lifecycle?
How long is the data science process?
Who is involved in the data science process?
Is one step in the data science process more important than the others?
What is Domino Data Lab?