HYBRID AND MULTI-CLOUD INFRASTRUCTURE
Data science across any cloud, region, or on-premises
A recent survey found that 71% of AI infrastructure decision-makers view hybrid cloud support as important for their AI strategy, of which 29% say it’s already critical.
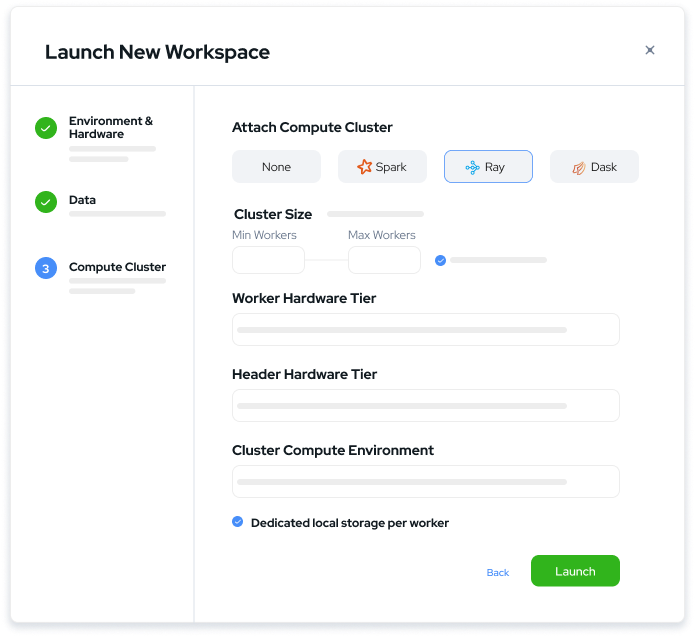
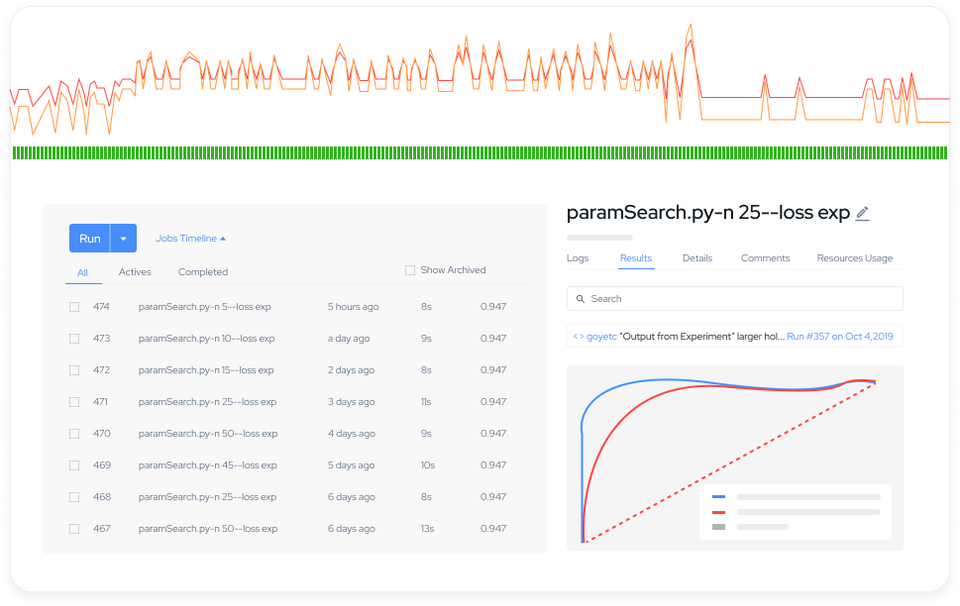
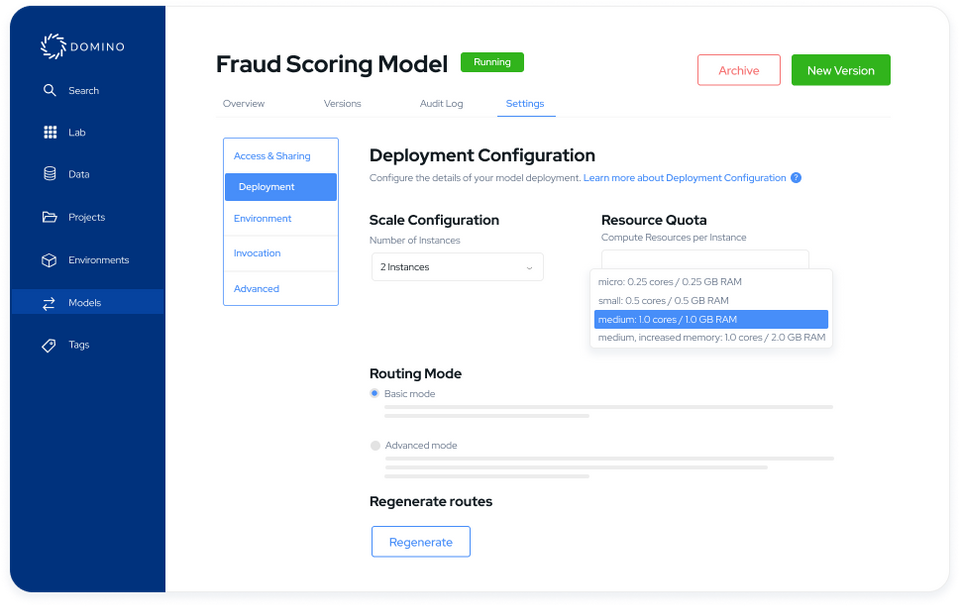
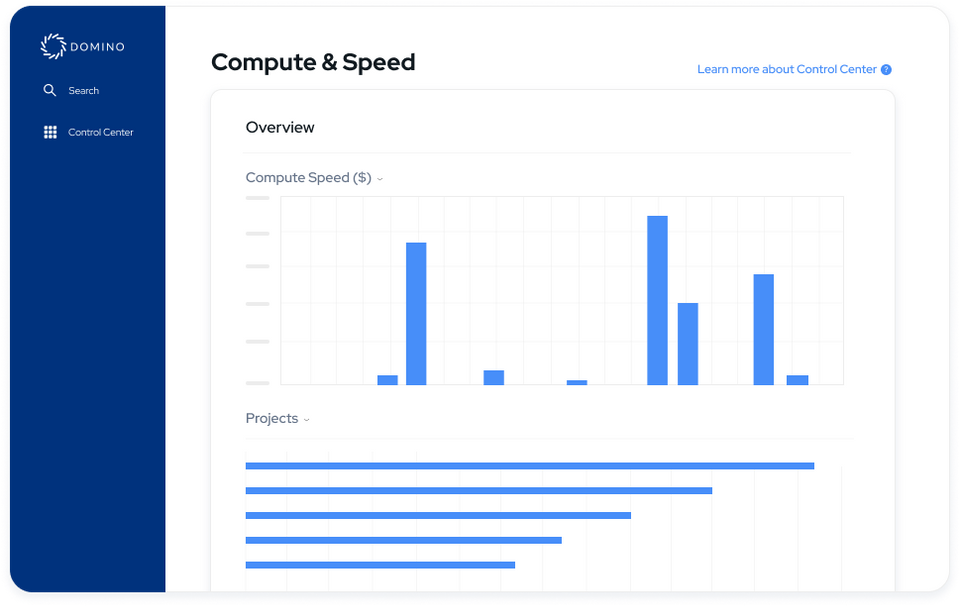
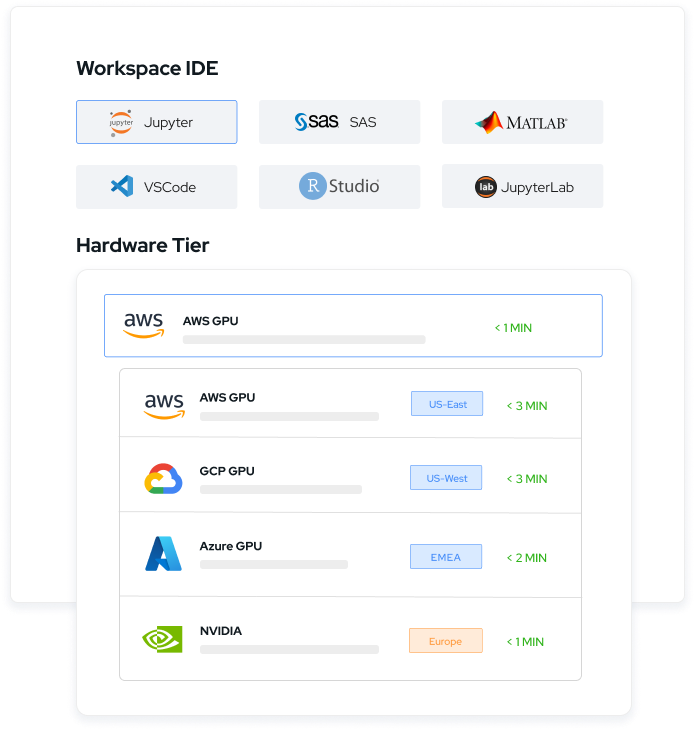
Domino Nexus is a single pane of glass that unifies data science silos across the enterprise, so you have one place to build, deploy, and monitor models. Protect data sovereignty, reduce compute spend, and future-proof your infrastructure.