Domino 4.4 Liberates Data Scientists to Maximize Productivity
Bob Laurent2021-06-21 | 9 min read

By Bob Laurent, Sr. Director of Product Marketing, Domino on June 21, 2021 in Product Updates
Last March, when the effects of COVID-19 were just starting to impact businesses, data scientists were on the front line in many companies to quickly rebuild models and help executives navigate during unprecedented times. And now, as the world is opening back up and companies are adapting to a new normal, once again it’s data scientists who are analyzing data, building (and re-building) models, and helping progressive companies capitalize with new data science use cases and, in some cases, entirely new business models.
If it wasn’t clear 15 months ago, it’s certainly clear now. Data scientists are driving the world’s most sophisticated companies to solve the world’s most important problems. In November, I wrote about why being a data scientist is still the “sexiest job of the 21st century” almost a decade after Thomas Davenport and D.J. Patil made that assertion in Harvard Business Review. Glassdoor ranked “Data Scientist” as the “Best Job in America” from 2016-2019, and after a drop to #3 in early 2020, it’s back to #2 in 2021.
Data scientists are special
Why? What they do takes unique skills, insights, and experience – highly complex work that is part science and part art. They need deep domain expertise about the business and also the freedom and flexibility to innovate – using the latest data science tools and techniques. They also need access to powerful infrastructure, including GPUs and distributed compute frameworks, to perform the complex analyses that are a daily part of their job.
Many companies, and especially the ones with large data science teams, understand this requirement, but unknowingly put barriers in the way of data scientists that limit their productivity. For example:
- Data scientists can’t get access to the tools and compute they need, and often spend more time solving DevOps challenges than doing productive data science work.
- They can’t find and reuse past work. Data scientists waste valuable time “reinventing the wheel” with each project because there are no established standards or best practices for data science.
- Models and model artifacts (e.g. apps/APIs) need iteration, but the use of different tools, languages, and packages (and different versions of each) makes it hard to collaborate with other data scientists and business stakeholders.
- Getting models into production is slow and hard when there are no consistent ways of working. And if a model is lucky enough to make it into production, inconsistent or non-existent model monitoring practices consume a significant amount of data scientists’ time.
The freedom and flexibility that data scientists want are often at odds with the control and governance that IT insists on. Companies have to make tradeoffs, and as a result, data scientists are often forced to use solutions that are limited in functionality and don’t provide the freedom to jump between the best tool for the job at hand.
Domino advocates for data scientists
We understand that data scientists are at their best when they’re not having to think about how to get technology working so they can focus on the business problem at hand. Our platform has always provided data scientists with self-serve access to the tools and scalable compute they need to be more productive. We believe in letting them work the way they want to work so they can get to work faster and be productive immediately, with no more wasted time on DevOps issues to solve infrastructure challenges.
“With Domino Data Lab, they’re free to do what they need to do, and they never have questions about technology – because they just get on with it. Like a musician playing a piano, or picking up a violin.” – Stig Pedersen, Head of Machine Learning, Topdanmark
Today we’re proud to announce Domino 4.4. This release builds on this vision with a re-imagined workspace experience – a next-generation data science workbench for data science where the most important capabilities that data scientists need to maximize their productivity are at their fingertips. You can think of this like a cockpit in a modern F-35 fighter jet when information is always available, and all of the most important capabilities that the pilot needs are right at their fingertips.

New capabilities help to maximize productivity
Most vendors force data scientists into a serial workflow that involves opening a single workspace, doing their work, committing the results, and then closing the workspace before moving on to the next task. With Durable Workspaces in Domino 4.4, data scientists can operate in a parallel workflow where multiple development environments can be open at the same time for maximum productivity. Users can start, stop and resume workspace sessions as needed (to save infrastructure costs), with work that persists from session to session. This ensures that they never lose work and are able to commit their work to version control whenever they want.
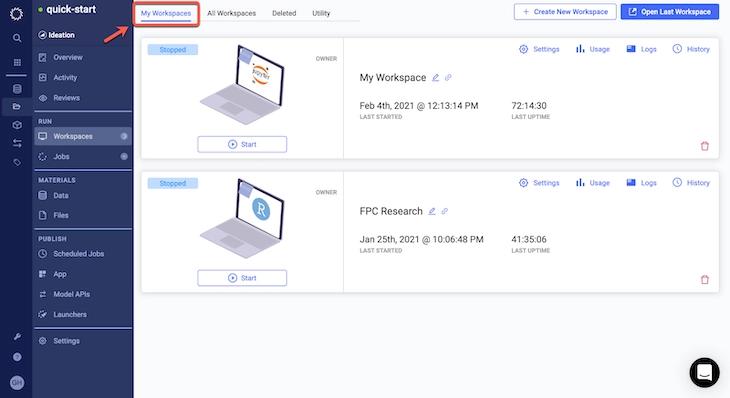
Domino automatically tracks all artifacts of experimentation so data science work is reproducible, discoverable, and reusable – increasing the throughput of data science teams and mitigating regulatory risk. These artifacts are documented as part of the Domino File System (DFS), but many companies prefer to use a centralized code repository based on Git (e.g. GitHub, GitLab, Bitbucket) so data science code can be integrated with the rest of their company’s CI/CD workflows to improve compliance and governance.
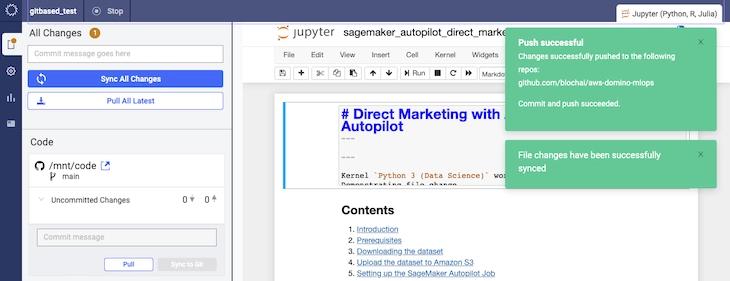
Domino’s market-leading reproducibility capabilities are now enhanced by CodeSync so data scientists can work seamlessly within the modern IT stacks used across their business. CodeSync supports all of the common Git workflows such as creating branches, committing code, pushing changes, and more – all from within a Domino workspace to/from the Git service provider of your choice. This Git-first experience gives users more control over the syncing and versioning of complex workflows, and makes it easy for them to engage in version-controlled, code-based collaboration with other team members.
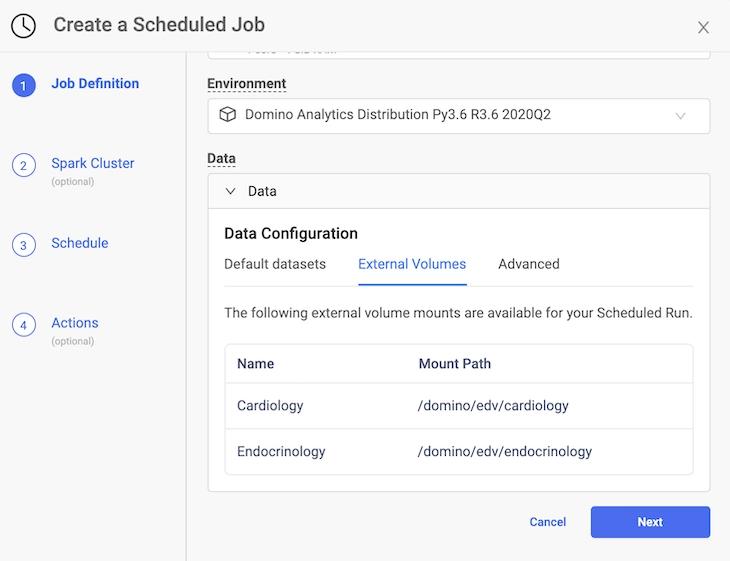
Data scientists want to utilize a variety of different types of data from multiple sources for better experimentation. Cloud-based solutions require data to be copied into the cloud, which introduces security and synchronization concerns. In Domino 4.4 we’ve made it easier to connect to External NFS Volumes so data scientists can use more types of data outside Domino for greater experimentation. And, they don’t have to move data around like they would with inflexible cloud vendor tools.
But, sometimes it’s necessary to move data between sites, which places it at risk if communications are intercepted. The last feature I’m going to mention isn’t a productivity enhancement per se, but it will make data scientists and IT teams sleep easier. Domino 4.4 supports Encryption in Transit with Transport Layer Security (TLS) – an industry-standard method for protecting data in transit.
Wrap up
These new capabilities make it easier for experienced data scientists to maximize their productivity, but they also benefit new and novice data scientists so they can onboard faster and contribute in meaningful ways sooner. Our new workspace experience removes the “cold-start” barriers that many new data scientists face with other platforms regarding setting up environments, managing libraries, spinning up workspaces, and more. The IT teams we’ve shown this to appreciate that they can provide governed and secure access to new users with guardrails in place that protect against lost work, unintentional runs, and significant cloud compute bills.
Existing Domino customers can upgrade to the new release now. If you’re not a Domino customer, consider what Forrester Consulting determined when they analyzed theTotal Economic Impact of the Domino Enterprise MLOps Platform.

Bob Laurent is the Head of Product Marketing at Domino Data Lab where he is responsible for driving product awareness and adoption, and growing a loyal customer base of expert data science teams. Prior to Domino, he held similar leadership roles at Alteryx and DataRobot. He has more than 30 years of product marketing, media/analyst relations, competitive intelligence, and telecom network experience.
RELATED TAGS
SHARE



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.