
Paco Nathan‘s column covers themes that include open source, "intelligence is a team sport", and "implications of massive latent hardware".
Introduction
Welcome to our monthly series about data science! Themes to consider here:
- Open Source wins; Learning is not enough
- Intelligence is a team sport
- Implications of massive latent hardware
Also, the first item to mention: we’ve got a panel discussion coming up at Domino HQ on Thursday, November 8th, in SF, "Data Science Versus Engineering. Does It Really Have To Be This Way?” – featuring Amy Heineike, Pete Warden, myself, and our mellifluous moderator Ann Spencer. Join us for a lively discussion about collaboration for developing and deploying ML models. See below for details on where Amy and Pete are making waves in data science, and we look forward to meeting many new folks at the panel!
Open Source wins; Learning is not enough
Data Science, let’s break this down into components:
- Code: iterative process (among others), thanks to SLDC, Agile, Kanban, Lean, etc., help guide teams to refine software as intellectual property, and the results are probably managed in Git repositories (or some other versioning system)
- Data: it accumulates (in vast quantities, as we’ll see below) while we curate it, prep it, analyze it, monetize it, audit it, etc.
- Models: generalizations which are structured by the code, yet learned from the data
Strong notions about software engineering blossomed two decades ago. These days, in most enterprise circles, it’s difficult to talk about “code” without someone mentioning the word “agile” as well. Hence, there are strong inclinations to apply this descriptor to many other activities,(“Agile Data”, “Agile Modeling”, etc.) which, in my experience, is a very bad idea. Ron Jeffries, one of creators of Agile methodology, recently advised that developers should “detach from named methods.”
Data used to be a relatively simple thing. The person writing code also defined a data model, then a program’s execution was deterministic: input goes into the program, processing happens, output comes out. Done and done. That reality crumbled somewhere in the late aughts. Now we have “data-driven” companies everywhere. Code became cheap. Google will give you their ML code; but you won’t get their (curated) data, nor will you get their organizational learnings.
An exec at a large software firm said to me recently, “Open Source won, we recognize that now.” It’s likely that much, or even most, of the code your organization relies upon gets maintained by someone outside of your organization, via open source projects. Let’s start with Linux, then move to Git, Docker, Kubernetes, Python, etc. See the point? Agile code development probably isn’t where your data team focuses its value creation activities. While a burgeoning number of data science bootcamps, undergrad programs, etc. focus on nuances of developing different kinds of ML models, in daily practice, your data team probably spends its valuable time munging the aforementioned data: how to curate it, prep it, analyze it, monetize it, audit it, etc., plus creating data infrastructure to collect it, store it, make it available, query it, etc.
That said, there are some excellent insights into open source vis-a-vis data analytics infrastructure. In case you weren’t reading the news recently, there have been at least three ginormous mergers and acquisitions (1, 2, 3) including, arguably, the largest pull-request in history. Felipe Hoffa at Google BigQuery has a Twitter thread and blog post about how to identify what’s really trending in popularity among developers, based on Stack Overflow data at scale. Moreover, for technology companies, winning mindshare from developers at other companies is becoming more important than traditional marketing and now almost every company is becoming a technology company so this point matters. But I digress.
https://twitter.com/DynamicWebPaige/status/915326707107844097
ML eats Software, talk by Jeff Dean / photo by Paige Bailey
The word learning is not even mentioned in the Agile Manifesto. Machine learning began “eating” software several years after the Manifesto was written. We’re now seeing how large code bases can be replaced by learned models. Reports from Google this is “happening every day across hundreds of projects.” In some interesting cases, ubiquitous algorithms which developers have spent decades honing, are being replaced by learned models. On the horizon we see will QA teams working on machine learning apps which generate unit tests. This will have significant impact on how code gets written. Even so, many teams I encounter in industry exhibit the anti-pattern of placing too much emphasis on code, not enough emphasis budgeted on data, and relatively little emphasis on learning as a team. More about that in just a bit.
Meanwhile, learning is not the full game in AI. Here’s an excellent insight from Jana Eggers at Nara Logics:
You have to manage your data, your algorithm, and your objectives for bias. It’s a trinity whose strength can also work against you or for you.
Aha, objectives matter as well. Plus, as James Cham at Bloomberg Beta explored in a Twitter thread, supervised machine learning is inherently reactionary. That’s something to consider. Kristian Hammond presented at keynote at AI London earlier this month, emphasizing the point that AI is many things, not simply learning.
So, code + data + learning are necessary, but not sufficient. What would be sufficient? How do we reach something akin to an Agile Manifesto which applies to data science?
Toward that point, Fernando Pérez at Project Jupyter shared practices for keeping a PDF (i.e., a published article) “linked to background details, interactivity and reproducibility support.” In other words, how to publish papers which stay relatively up-to-date and support reproducible science. A recent article in Nature explored reproducible workflows based on Jupyter. Fernando, along with Peter Rose at UCSD Bioinformatics, et al., recently published Ten Simple Rules for Reproducible Research in Jupyter Notebooks. I started a thread about that on LinkedIn.
Do your experiences in data science work agree with that?
Intelligence is a team sport
Deep learning (DL) experienced an inflection point in 2012. There’d been code available for years, but it took a while for a good dataset to illustrate the amazing value of that approach. Plus, GPUs could be leveraged to make the massive computational requirements more feasible.
Natural languages (NLP, NLU, NLG, etc.) are reaching an inflection point. Like for DL, there’s now great code, excellent datasets, sufficient hardware, etc. Even so, I’m appalled to see smart people still referencing NLTK, bag-of-words, stemming, etc., in 2018, when this field has recently experienced an explosion of advances.
I got to participate in the Big Data A Coruña conference earlier this month, hosted by Amparo Alonso and David Martínez Rego, where Dani Vila Suero presented a survey of the latest NLP papers from ICML – which was overwhelming to the audience. AllenNLP has ELMo out for “deep contextualized word representations,” then Google anteed up with BERT. Later that week I joined Dani and entire the Recogn.ai team for a wonderful company retreat in Asturias, focusing on NLP, sidra, fabada, and other Asturian delights. If you want to keep informed about the latest in NLP, Dani recommends http://nlpprogress.com/ site.
https://twitter.com/recogn_ai/status/1048588248010960896
Recogn.ai in Asturias, shortly before we left to dine on sidra and barnacles
So much of what we see getting called “AI,” and also so much of the commercial focus on natural language, seems to center on chatbots. Questionable claims about commercial bot software are abound, but some of the best work on NLP for dialog is coming from a popular open source library called Rasa. Check out this interview with Alan Nichol, the lead on that project for their unique perspectives: The O’Reilly Data Show Podcast: Alan Nichol on building a suite of open source tools for chatbot developers.
Back at AI London, Amy Heineike presented other excellent natural language work during a packed keynote which included a marathon Q&A session, an indicator of the audience response. Amy and I recorded a video interview, where she details key insights about natural language work that allows Primer.ai to field AI products that solve hard problems. One core insight about human-in-the-loop practices Amy emphasized:
…people excel at precision, machines are better at recall, what’s important is to blend the best of both worlds…
Another fantastic point from Amy is to consider AI products for text in three stages:
- read (i.e., NLP)
- analyze (i.e., NLU)
- write (i.e., NLG)
There are inherent trade-offs at each stage, depending on how much the people or the machines can handle respectively. While many companies seemingly strive for magical AI algorithms which can solve their business problems in one fell swoop, Amy cautions that we should consider how “intelligence is a team sport,” how cognition propagated through a team allows the AI process of read/analyze/write to create drafts which an expert team can use and amplify for their business objectives. Wise advice indeed!
In fact, this theme echoes among other case studies for active learning, aka human-in-the-loop. B12 creates and updates business websites, where only the final stages of their pipeline are performed by human designers and programmers. Among the big fish, Ernst & Young (EY) similarly uses human-in-the-loop with an “intelligence is a team sport” approach in their lease accounting compliance practice, resulting in 3x more consistency and 2x more efficiency than their previous humans-only teams.
I presented a talk about active learning case studies, with the summary diagram:
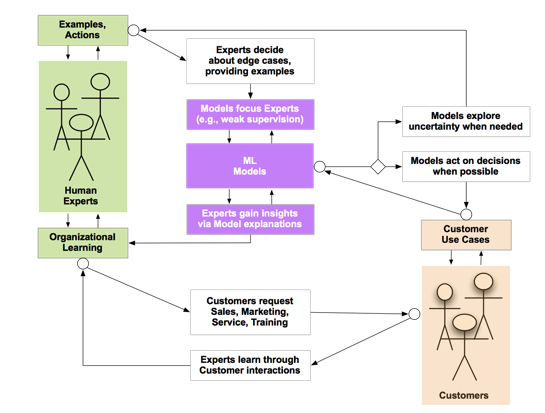
The gist borrows a gem from Michael Akilian at Clara Labs:
The trick is to design systems from day 1 which learn implicitly from the intelligence which is already there.
In other words, building on Amy’s insights, “intelligence is a team sport” and your organization already has people who are domain experts in what your business needs to do. They propagate organization learning over time, across the team leveraging the intelligence which is already there. Any AI app that you deploy needs to be considered as a mix of team of people + machines. Also, borrowing from cybernetics (and the origins of machine learning, specifically the first neural network project in the 1940s), we need to conceptualize hard problems in AI less as “black boxes” with linear input/output, and more as dynamic, almost organic systems of cognition where there are two-directional feedback loops at every point of interaction.
To wit:
- Deployed ML models interact with customers (use cases)
- Customers interact with domain experts (professional services, customer support)
- Domain experts interact with ML models (training datasets, active learning, ML model explainability, etc.)
Each of these feedback loops must be a two-way street. For the curious, there are computable formalisms for feedback loops, called conversations for action. FWIW, Google emerged from the Stanford lab where this work was explored, and if you really want to learn about the history involved, check out Project Cybersyn.
Implications of massive latent hardware
Some pain-points in industry arrive from unanticipated directions. Because one needs huge clusters to train ML models on Big Data, the words machine learning tend to make people think about huge data centers: ginormous buildings full of computing equipment, networking, etc., probably co-located near some remote renewable energy production facility. However, that mental image was so 2017.
You may have seen recent news about Microsoft building hardware for the edge, to bring data into the cloud. Expect more of that in the day-to-day practice of data science, with emphasis on the keywords hardware, edge, and cloud. On the one hand, the amount of data in databases (e.g., your bank records) is relatively small when compared with the amount of data produced in web app interactions and other Internet-ish activities. For measure, consider that tweets sent on Twitter generate ~0.15 terabytes/day of data. On the other hand, as many IoT reports have mentioned, this metric is trivial when compared with data rates out in the field. Financial exchanges generate ~5 terabytes/day. Weather data worldwide is 4x that, for ~20 terabytes/day. A single large telescope array produces more than that amount each night. In 2015, hospitals were estimated at ~665 terabytes/day. Meanwhile, from the 25,000 commercial flights flown daily, we get roughly 18x, more than ~12 exabytes/day. All totaled, even those data rates are negligible compared with estimates of ~30 terabytes/day for each self-driving vehicle, multiplied by 1.2 billion light-duty vehicles on the road currently. Think about how much data commercial vehicles will add to that figure?
Rough estimates put the data needed for ML model inference on the edge well within yottabyte territory. However, basic laws of physics preclude sending that data “up to the cloud” for processing and back again. The math and physics say we must run ML models on the edge. For instance, running models within hardware installed in commercial trucking fleets (a really ginormous, ubiquitous, valuable kind of use case).
https://twitter.com/aallan/status/1055874656761249793
“Blue Pill” board, by Alasdair Allan
Enter the magic combo of hardware, edge, cloud. Note that there’s nothing particularly magical about GPUs w.r.t. deep learning. If you’re building hardware for neural networks from scratch, you’d optimize for low-level linear algebra libraries and probably wouldn’t end up with anything resembling a GPU. For an excellent discussion, check out The O’Reilly Data Show Podcast: Andrew Feldman on why deep learning is ushering a golden age for compute architecture.
Then watch a must-see video interview Pete Warden and I recorded at AI London. Pete was showing recent work at Google based on the “Blue Pill” STM32-compatible microcontroller boards being manufactured in mass quantities in China. Notably, these devices cost $0.50 each, much less if you buy in bulk. They provide all the hardware you need to run deep learning inference based on TensorFlow.js in a low-power, embedded application.
Recent research at Stanford has shown how deep learning models can be transformed to run on low-precision hardware with high accuracy, often reduced in size by several orders of magnitude, and running up to 4x faster. Pete demonstrated how to run TensorFlow models for video recognition, image, voice, etc., in 20K RAM – with no operating system. In other words, signals come in directly, run through a DSP, then through DL models inference. These “Blue Pill” devices are small enough to be powered by photovoltaics using ambient room light; no batteries needed.
Pete executed exquisite mic drops on a few other key points. First (aside from their obvious utility as cat toys) think about ways to combine voice and visual commands, i.e. sensor fusion. For example, consider a noisy restaurant environment where several people are talking and make it nearly impossible for deep learning to convert speech-to-text reliably. However, if a person points at a device (camera) and says a command (mic), then a 20K TensorFlow model can infer reliably.
Second, while these “Blue Pill” devices aren’t large enough to support radios or other network connectivity, they are capable of being “always on,” ready to interpret voice/visual commands which in turn “wake up” other larger hardware devices that do have connectivity to cloud-based AI services. In other words, consider having ubiquitous, cheap hardware devices – deployed in the field with no need for power, connection, maintenance – which can leverage AI to bridge into the cloud on demand.
Third, there are already a half billion of these devices deployed worldwide. This means there exists massive latent hardware on which we can deploy ML models. Ready and waiting. To me that’s both ominous and fantastic. A game-changer.
Speaking of DSPs, while in London I also got to interview Gary Brown at Intel AI about their work producing new forms of hardware for the edge. Intel has released the OpenVINO toolkit to deploy ML models in low-power applications, similar to what Pete’s team at Google is doing. For example in the general, case cameras keep getting smarter, whether we’re talking about security or retail or medical imaging and ML models are becoming embedded in cameras. Extending on that example, factories are becoming upgraded to “visual factories” using these kinds of latent camera+ML hardware. In other words, the factory infrastructure itself can detect hazards and issue safety warning on site – with no need to send all the data up to the cloud and back. Subsequently, aggregated data or metadata can be sent to the cloud for post-processing.
As a callback to edge data rate stats above: Gary described the outlook over the next five years, where the value of AI inference is projected to grow 25–30% yr/yr, with most of that growth at the edge rather than in data centers.
To put this all in context: Pete described how to leverage massive latent hardware which exists today at scale; Gary described how newer forms of hardware are pushing those effects to a much larger scale; and Amy described how to leverage these advances for “intelligence as a team sport”, i.e., not having to wait for magical AI algorithms which perform unimaginable tricks without people in the mix. Instead, plan all of your technology rollouts in terms of teams of people + machines, then adjust the mix as needed.
Interestingly, rather than data munging – on which data science teams allegedly spend +80% of their time – these edge AI applications take data directly into the hardware. That’s a significant change in process and engineering assumptions, one which has an impact at the yottabyte scale described above.
One of the meta-themes that I’ve been exploring in 2018 is how
hardware > software > process
In other words, hardware is evolving faster than software, and software is evolving faster than process. Numerous enterprise organizations give this “two thumbs up.”
Do your experiences in data science work agree with that?

Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.