![Launch new workspace screen [clean]](https://cdn.sanity.io/images/kuana2sp/production-main/c0d250b5ccad32843570dcd3d703cbedfdfb607c-861x717.png?w=960&fit=max&auto=format)
ON-DEMAND INFRASTRUCTURE
Instantly Access Your Favorite Tools and Compute
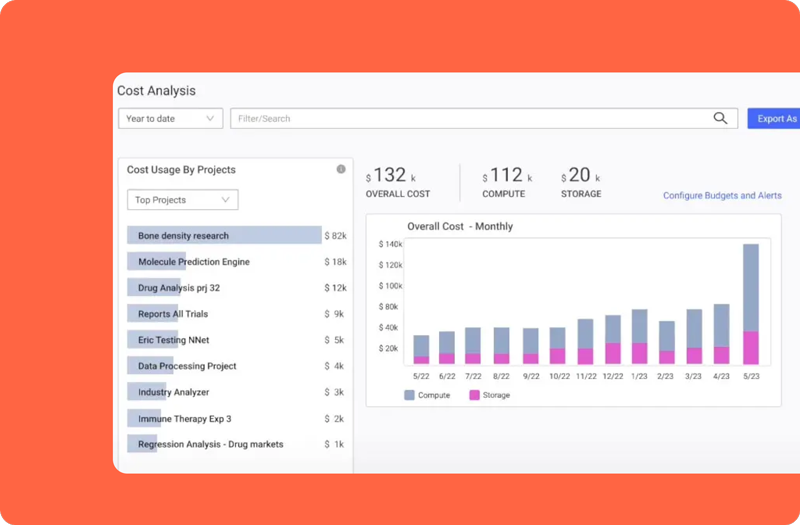
Domino provides data science teams instant access to compute, data, and your favorite open source or commercial tools. Data scientists can focus on creating value, while IT maintains control over software, infrastructure, and enterprise standards.
![Explore your data [clean]](https://cdn.sanity.io/images/kuana2sp/production-main/17f10bf07c5f1b65979d252ba54cd2fbef1fc986-937x576.png?w=960&fit=max&auto=format)
![experiment_B, Comparing 3 runs [clean]](https://cdn.sanity.io/images/kuana2sp/production-main/e86b2415e21511d2d255aed2454287a6ca5dbbde-1116x709.svg?w=960&fit=max&auto=format)
![Retirement simulation [clean]](https://cdn.sanity.io/images/kuana2sp/production-main/50af319e5d7c98b27727409f2c3a012b95b39c71-1100x676.svg?w=960&fit=max&auto=format)
![Census classifier FC [clean]](https://cdn.sanity.io/images/kuana2sp/production-main/bb25ed1c07f997266221bfd24eca412c579ea0e7-800x498.png?w=960&fit=max&auto=format)