My name’s Jack Parmer, and I’m the former CEO and co-founder of Plotly.
In 2012-13, when I was writing Plotly’s first product in San Francisco, I regularly ran into Nick Elprin and Chris Yang, two of Domino Data Lab’s co-founders. Nick and I kept in touch over the next decade as we each grew our companies and navigated our roles as first-time CEOs.
I have tremendous respect for what Chris and Nick have built. Perhaps more than any company in the past decade, Domino spearheaded bringing code-first Python and R data science into the Fortune 500. Through their platform and thought leadership, the Domino team has steadfastly removed every obstacle to scaling widespread usage of Python and R in the stringent IT environments of large enterprises, particularly those with strict regulatory environments such as banks, insurers, and pharmaceuticals. Analysis and model building with Python or R on Domino is seamless, fast, error-resistant, and collaborative.
I’m thrilled to talk about our step-change advancement in bringing the powerful capabilities of Python and R to enterprises everywhere. Domino is now shipping with Domino Code Assist (DCA), which auto-generates boilerplate Python and R code within an intuitive GUI. To illustrate its powerful range, here is some of the code that DCA can generate - with just a few clicks of the mouse:
- Data import: Importing data from Snowflake, S3, BigQuery, or RedShift into a Pandas or Dplyr Dataframe
- Data transformation: Visually “tidying” and filtering Pandas and Dplyr Dataframes (all with point-and-click)
- Data viz: Creating interactive data visualizations from Pandas and Dplyr Dataframes
- Data app creation: A Data App canvas to drag-and-drop elements from a Jupyter notebook (such as plots, tables, text, and Jupyter widgets)
- Data app deploy: A single-click deploy button for deploying and sharing Data Apps made within Jupyter notebook
These routine tasks are practically unavoidable in the day-to-day work of a data science practitioner (DSP). However, they take time and mental bandwidth away from their core expertise (such as ML model development and advanced statistics). Debugging an app deployment on the command line, copying Pandas or Dplyr syntax from StackOverflow, or Googling “connect to Snowflake with R” are arguably not the best uses of a DSP’s time. And, speaking from experience, they are also not the most fun.
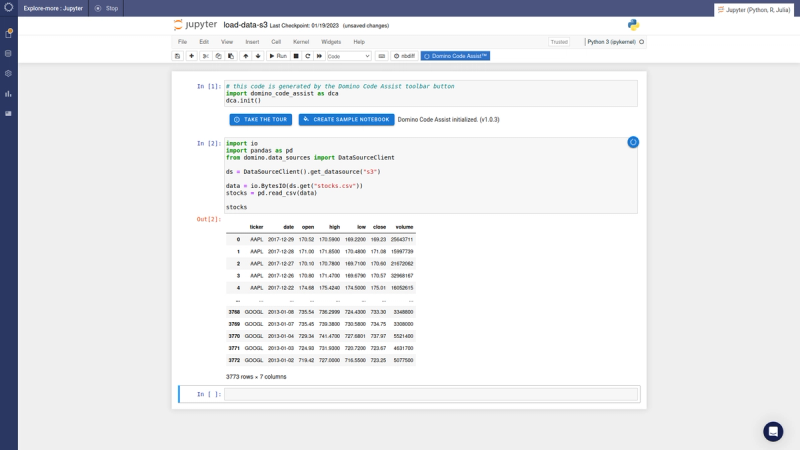
DCA lets Jupyter(Lab) and RStudio coders accelerate through this languid boilerplate and get to “the good stuff” faster. For example, here is how code generation for connecting to S3 in Python looks with Code Assist:
With just a few clicks results in the Python code below:
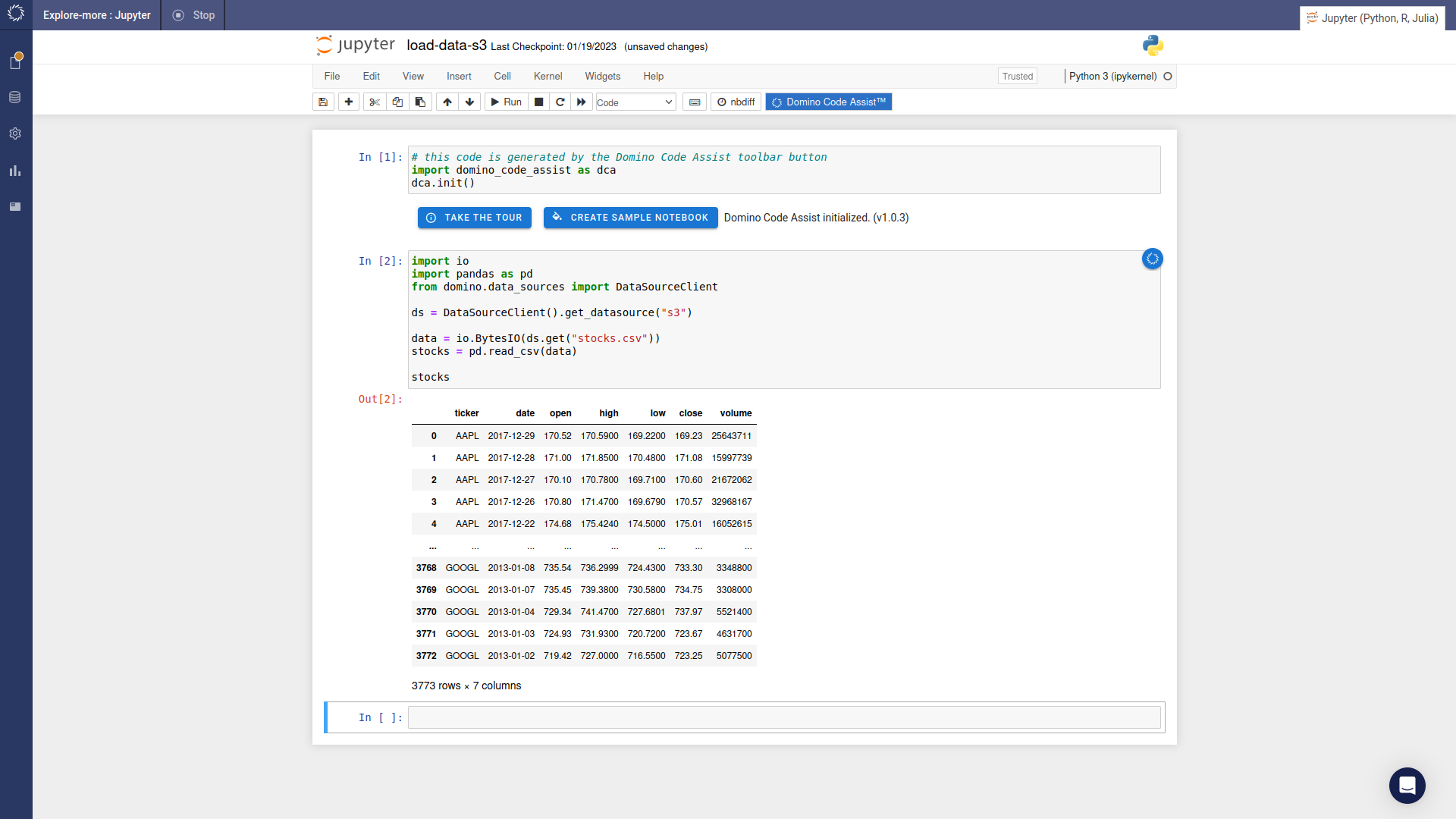
Even though I’ve been around data science in Python for 10 years, I would never commit the above database connection syntax to memory. It’s just too boring. I look it up every time. While not a big deal, it still represents a few minutes of mostly joyless, tedious drudgery. As shown in the above GIF, with DCA, I can simply click through this wizard while still generating reproducible, production-grade Python or R code.
Domino Code Assist is Code-First
Compared to other “low-code” tools on the market, Code Assist is unique in that it alwaysauto-generates and executes Python or R code as its end product. In this sense, there’s no black box magic - DCA simply generates strings of code based on your clicks in the GUI, then inserts and runs that code into your Python or RStudio session. Simple! All of the computation is always being done in Python or R with perfect code-first transparency.
When exploring what “low-code” could mean for the Domino platform, I wanted to honor the no-fluff, code-first ethos that makes data scientists trust Domino. With Domino, data scientists get a no-BS platform to run their favorite data science IDEs (mainly the Jupyter/RStudio/VSCode IDE trinity). DCA is true to this approach to data science - it accelerates rather than diverts code-first analysis.
Re-framing “low-code” data science as assisted code generation has many advantages:
- Portability: Because the end result is always Python or R code, analysis with DCA is perfectly portable. It can be productionized or downloaded and run off-platform.
- Skills-building: By generating Python and R snippets interactively through a point and click wizard, DCA is a powerful learning tool for analysts or aspiring data scientists.
- Tweakability: DCA can generate and run a “first draft” code block, which you can then tweak and rerun to get exactly what you want.
A Powerful Learning Tool
For new graduates, analysts, SMEs, or simply the curious, Domino Code Assist softens the learning curve for code-first analysis. Among our customers, we often hear that data scientists are in short supply and that DCA can help fill this shortage and skills gap by making it easier for analytically-oriented employees to build their Python and R skills. Code-first analysis in Python and R can be joyful, rewarding, and creative work. We hope that DCA encourages more no-code analysts to dip their toes into this powerful wizardry.
In DCA user testing, we found these encouraging results among novice and expert programmers:

In my next post, I'll walk you through the highlights of DCA. In the meantime, if you would like to get a demo, reach out to the team. You can also explore the DCA documentation here.

Jack Parmer was co-founder and CEO of Plotly and was instrumental in bringing the Dash framework for Python to market. At Domino, he leads the ideation and execution of major new product strategy initiatives in close collaboration with Domino's customers and leadership team.



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.