
Today Domino announced a revolutionary new capability that enables data science leaders to expand their talent pool, promote a culture of analytics around the enterprise, increase collaboration across teams, and ultimately deliver more value to the business.
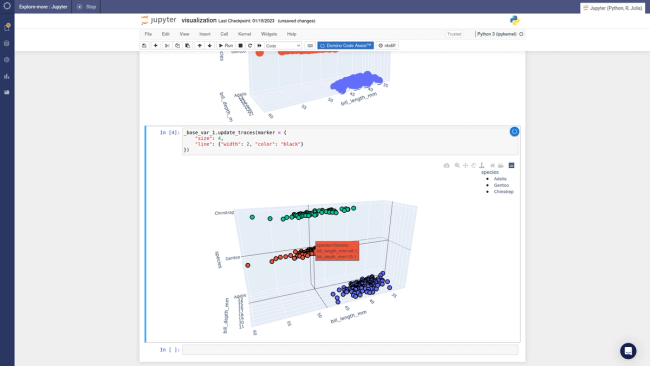
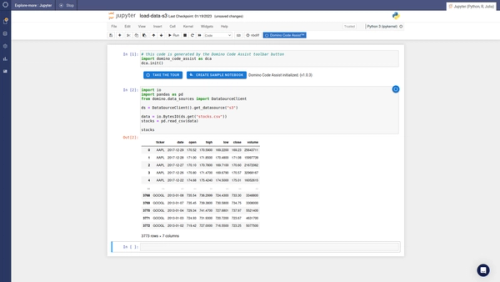
We call it Domino Code Assist (DCA). It lets anyone generate Python and R code for everyday data science and analytics tasks by making simple selections in a GUI. It's a simple idea that's incredibly powerful because it provides a new path for companies to transform their data science talent strategies and democratize access to analytics and AI throughout their organizations.
Coders vs. clickers: a misguided dichotomy
To appreciate the power of DCA, I want to set the stage by describing the challenge I’ve heard from customers and the unmet need we saw.
One challenge stands out when I speak with Chief Analytics Officers and other data science leaders: capacity constraints on their data science organization limit the ability of data science to realize its full potential to deliver business value. The problem becomes more acute as companies experience more success with data science because they identify so many new opportunities for impact.
To overcome these capacity constraints, some organizations have focused on hiring expert data scientists with advanced coding skills. In contrast, others pursued less technical talent using drag-and-drop, no-code, or "automated machine learning" solutions. It's the "coders" vs "clickers" debate.
Each of these strategies has challenges.
Expert data scientists can tackle the most complex and differentiated data science problems. As a result, they can have an outsized impact on the organization's performance. Yet hiring such talent is highly competitive, making recruitment expensive and slow.
But the alternate "clickers" strategy has significant challenges, too. We have seen drag-and-drop solutions work well for data prep and traditional business intelligence work but fall short for more advanced data science work. And "no code" autoML can often be a good start but inevitably require customization and fine-grained control in the context of advanced use cases.
Some organizations adopt a bi-modal strategy: coders work in Python or R on open platforms, while clickers work in a proprietary GUI tool. Unfortunately, the results are not much better. Each group works in its silo. Domain experts and analysts still cannot collaborate with data science experts. Neither group can reuse the other's work artifacts. Occasionally, the organization does notch a success and produces a useful model from the no-code tool. However, bringing that model to production requires fully re-implementing it in code, a convoluted and time-consuming translation process. Companies looking to move the needle need a different approach.
A better talent strategy: code as lingua franca
Throughout my two decades in data science, I've seen many teams lured by the siren song of "no code" and inevitably wind up disappointed. Meanwhile, the highest-impact data science organizations recognize and embrace code as a reasonable "cost of admission" to delivering results. For example, one CDAO at a prominent investment firm recently told me that newly revised job titles and descriptions required knowing how to code. That included even those with a "data analyst" title.
Code unlocks creativity, allowing data scientists to conduct thorough analyses, develop superior models, and solve more complex and unique problems. In addition, being text-based makes code easy to audit: It is rudimentary to trace differences in text files and simple to search through. These are essential requirements for proper version tracking and regulatory compliance.
Open-source languages also bring a treasure trove of ongoing innovation - for free. Any organization can harness cutting-edge advances like generative AI right now. Clone a library from Github and gain the opportunity to beat your competition with the latest and greatest advancements. There is no need to wait for a new release of a click-driven commercial product.
Low code is the perfect go-between
The first steps with code are often daunting. Translating thoughts to exact Python incantations to make things happen is a skill that develops over time. As a result, Domino — now with DCA — takes care of all the hard parts of programming. Most importantly, DCA offers a clear path to scaling a data science organization.
DCA helps expand the talent pool to analysts and subject matter experts who can contribute meaningfully to data science projects. It offers foundations for a career ladder for upskilling analytics professionals. Analysts can advance from Excel or SQL to Python and R and incrementally get closer to data science work, increasing engagement. DCA multiplies the impact of your most advanced data scientists, enabling the entire organization to reuse and build on their work. It empowers them to lead their peers and drives both productivity and retention. It makes all your data scientists more productive, even the ones already comfortable with code. And finally, DCA automates everyday data science tasks, speeding up the minutia-heavy aspects of data science projects.
Conclusion
DCA allows data science leaders to build a scalable, modern, and enduring talent strategy. A code-first talent strategy that will support the next generation of data scientists, whether they are coming from universities or upskilling from within your organization. A larger talent pool frees senior data science experts to focus on the most pressing, complex business problems. And with all researchers using a single platform, better collaboration and knowledge sharing can permeate across trained and upskilled data professionals.
Domino is just getting started with DCA. Our ambitious roadmap leads to more analytics task automation and further best practice implementation. In addition, we will continue enabling new types of multi-persona collaboration, sharing, and code reuse.
To learn more check out https://www.dominodatalab.com/product/code-assist.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
RELATED TAGS
SHARE

Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.