
In the multiverse of data science, the tool options continue to expand and evolve. While there are certainly engineers and scientists who may be entrenched in one camp or another (the R camp vs. Python, for example, or SAS vs. MATLAB), there has been a growing trend towards dispersion of data science tools.
As new team members with varying backgrounds are added, as new sources of data are made available from different platforms, or new deliverables are required from stakeholders, allegiance to a specific camp becomes counterproductive. Domino’s Enterprise MLOps platform was designed with this diversity in mind so that as your projects and data science tool ecosystem evolves, the options available to your team won’t be limited to a single approach.

What Are Data Science Tools?
Like most professionals, data scientists require specialized tools in order to do their work efficiently. These data science tools are used for doing such things as accessing, cleaning and transforming data, exploratory analysis, creating models, monitoring models and embedding them in external systems.
Types of Data Science Tools
Tools may be open source or commercial. They may be GUI based or require extensive programming experience. Some are very specialized and others are much more of a “swiss army knife” type that can perform a wide variety of functions. Key categories of tools and a few examples include:
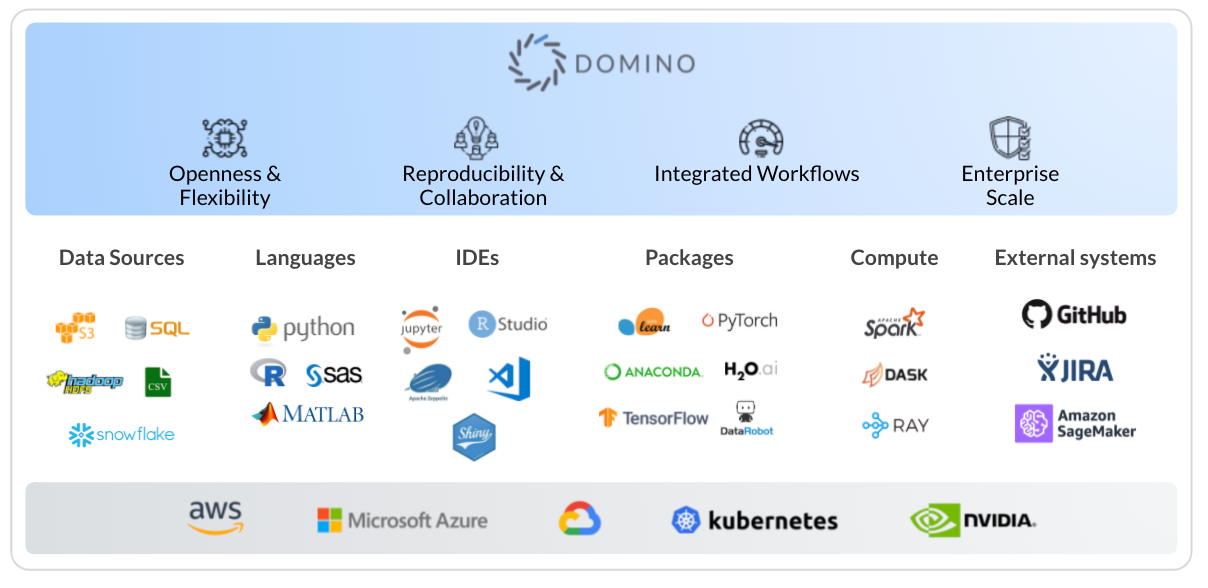
Data Sources
Data sources used by data scientists are nearly endless. They range from flat files (e.g. csv) to relational databases (e.g. SQL based) to big data stores (e.g. Hadoop) and cloud databases (e.g. Snowflake). For data scientists they need a way to access those data sources easily and cleanse, transform, and combine data.Often the processing power of the database may be used for complex computations or scoring of records. Once data access happens they frequently use a favored language/IDE to do data wrangling prior to analysis.
Data Languages
Languages are typically broken into two categories, commercial and open source. SAS and MATLAB are the two big commercial languages. MATLAB is both a proprietary programming language and a software platform used for integrating a large volume of data, functions and algorithms. Similarly, SAS is a language and software platform, and renowned for its ability to handle large amounts of data and broad analytic capabilities.
The most popular open source languages today are R and Python. R is a programming language used for a wide variety of data science tasks, with its capabilities being extended through packages and different IDEs. Originally created for software development, Python is used in a variety of contexts, including deep learning research and model deployment.
Data scientists are very opinionated in what languages they prefer for different types of tasks. It's critical that they have easy access to them in their most current version so they can efficiently do their job, without having to build out environments manually each time they want to do a model.
Integrated Development Environments (IDEs)
IDEs (also sometimes referred to as notebooks) is a coding tool that makes it easier to develop and test code. They provide a single place to, among other things, bring different packages together, prototype models, integrate with repositories and organize work. Some common IDEs are RStudio and Jupyter Notebook. RStudio is an IDE for the R language used primarily for statistical analysis as well as data visualization. Jupyter Notebook is a Python IDE that allows data scientists to create and share code, equations, visualizations and narrative text.
As with data science languages, programmers are very opinionated about the IDEs they prefer to use.
Packages
Packages are a grouping of code modules that provide specialized functionality or programmatic building blocks within an IDE or language. They save data scientists a great deal of time by eliminating the need to write code from scratch every time they build a model. Examples include Shiny, PyTorch and Tensorflow. Shiny is an R package that enables building interactive web applications that can execute R code on the backend.PyTorch is primarily used with Python for high level features such as computation on multidimensional data arrays and provides strong GPU support. TensorFlow is an open source framework for machine learning that is particularly focused on training and inference of deep neural networks.
Compute
Data science is computationally intensive and therefore data scientists need easy, fast access to appropriate compute environments - whether in the cloud or on premise. Graphical processing units (GPUs) are specialized circuits designed to accelerate computer graphics and image processing. They have become a critical requirement for algorithms that process large blocks of data in parallel. The key for data scientists is to create self service access to these environments so they don’t waste time DevOps tasks trying to get their environment set up.
Libraries
Compute libraries and engines such as Spark, Dask and Ray are designed to accelerate the processing of large amounts of data for a wide variety of data science use cases, improving productivity and the ability to leverage more computationally intensive algorithms.
External Systems
Data scientists working at scale need a way to track work and collaborate with each other. Two common systems that are also used by the application development world are GitHub and Jira.
Critical Considerations when Selecting Data Science Tools
Data science tools need to be efficient and relatively easy to use. Often, coding has to be done manually, but the less this is required, the faster and more efficient the work will be. Consequently, features like GUIs and data visualizations are practically a standard in most data science tools. Packages and libraries also contribute to the speed of work, by eliminating routine tasks. That efficiency extends to tools working together smoothly to avoid recoding of models or reformatting of data before work can continue.
When looking at tools that automate major steps in the data science lifecycle (such as AutoML tools) be sure you can leverage your data scientists to make improvements to the models, to ensure you can gain the most competitive advantage. One approach is to do proof of concepts with tools that automate much of the work and then build your final production ready model with code.
Pervasiveness of a tool is also important. New tools are constantly appearing and may have appealing features. But you need to think about support, the ability to get team members and the amount of rigor that goes into the update and support of that product prior to adding it to your ecosystem.
One of the most important features of any tool that is never listed in its tech specs is the affinity users have with it. You’ll notice, for example, those who have been using R for years are often resistant to Python, while those who are well-acquainted with MATLAB will prefer it over anything else. At the same time, when a different tool can be shown to do the job better than what they have been using, data scientists, by nature, seldom refuse a call to innovate.
Data Science Tools: Integration in a Enterprise MLOps Platform
In an enterprise environment, it's critical that the data science tools in use are able to work in concert with each other, regardless of their base language or differences in their structure. If work has to be re-coded in order to move into production or data has to be reformatted with an intermediate program before use, that is a huge waste of resources and has the potential to introduce errors and break lineage.This is where an Enterprise MLOps platform comes in, providing a place where different tools can be used on the same project for a seamless, efficient experience.
The Domino Enterprise MLOps Platform
Bringing all of these tools together is one of the benefits of the Domino Enterprise MLOps Platform.
It includes four key tool areas to build, train, deploy and manage multiple models on a centralized platform purpose-built for collaboration:
- Workbench: Allows you to build and run different models, while comparing results between them.
- Launchpad: Allows you to publish your deployed models in different formats.
- Domino Model Monitor: Allows you to monitor the performance of models in production from a single portal.
- Knowledge Center: Allows you to easily find and reuse project results across your enterprise, while maintaining consistent standards and best practices throughout your organization.
In an enterprise environment, where you have a variety of talented team members with diverse backgrounds all working together, it’s important for them to be able to focus on their expertise while being able to collaborate with others. With Domino’sEnterprise MLOps platform data scientists have the platform they need to bring the best tools for the project together, ensure an efficient workflow, and easily collaborate with each other..
To see the Domino Enterprise MLOps Platform yourself, you can register for a free trial, or watch a demo of the platform in action.
David Weedmark is a published author who has worked as a project manager, software developer, and as a network security consultant.

David Weedmark is a published author who has worked as a project manager, software developer and as a network security consultant.
RELATED TAGS
SHARE



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.