Getting started with K-means clustering in Python
Dr J Rogel-Salazar2025-06-23 | 11 min read
Whether you're a marketer looking to segment customers, a lawyer grouping documents by theme, or a financial analyst identifying transaction patterns, clustering is a powerful tool in your data science toolkit. As a cornerstone of unsupervised learning, it helps you find natural groupings in your data when you don't have predefined labels.
As we've covered in our post on the difference between supervised and unsupervised learning, we turn to these methods to explore inherent patterns without relying on existing labels. While many clustering algorithms are available, including powerful techniques like density-based clustering, it’s often best to start with one that is both effective and intuitive: K-Means.
In this tutorial, you will learn:
- The core concepts behind K-Means, including centroids and distance metrics.
- How to implement the K-Means algorithm from scratch using Python.
- A practical method for choosing the optimal number of clusters (k).
- How to leverage the powerful and optimized Scikit-learn library for K-Means clustering.
You can run the code in this post on your own machine or use the Domino Enterprise AI platform to access the project directly. Let's get started.
Understanding K-Means
The fundamental idea behind K-Means is to find commonalities by measuring the distance between data points. The closer two points are, the more similar they are. K-Means most commonly uses Euclidean distance—the same straight-line distance we learn in the Pythagorean theorem.
Let us take a look and consider two data observations over two attributes, a and b. Point p1 has coordinates (a1,b1) and point p2 has coordinates (a2,b2).
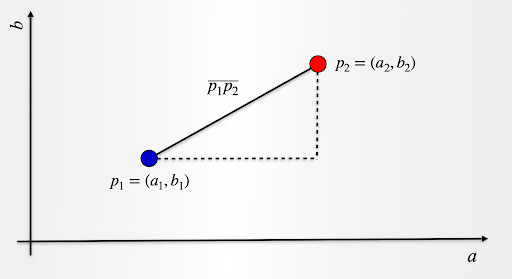
The distance p1p2 is given by:
p1p2=sqrt((a2−a1)^2+(b2−b1)^2)
The expression above can be extended to more than two attributes to measure the distance between any two points. For a dataset with n observations, we assume there are k groups or clusters, and our aim is to determine which observation corresponds to any of those k groups. This is an important point to emphasize: the algorithm will not give us the number of clusters. Instead, we need to define the number k in advance.
In a nutshell, K-Means clustering tries to minimize the distances between the observations that belong to a cluster and maximize the distance between the different clusters. In that way, we have cohesion within a group, while observations that belong to a different group are kept further apart. Please note that as we explained in this post, k-means is exhaustive in the sense that every single observation in the dataset will be forced to be part of one of the k clusters assumed.
But what about the "means" part? As part of the algorithm, we are also looking to identify the center for each cluster. We call this a centroid, and as we assign observations to one cluster or another, we update the position of the cluster centroid. This is done by taking the mean (the average) of all the data points that have been included in that cluster. Easy!
The K-means algorithm: A step-by-step recipe
The recipe for k-means is quite straightforward.
- Decide how many clusters you want, i.e. choose k
- Randomly assign a centroid to each of the k clusters
- Calculate the distance of all observations to each of the k centroids
- Assign observations to the closest centroid
- Find the new location of the centroid by taking the mean of all the observations in each cluster
- Repeat steps 3-5 until the centroids do not change position
Getting started
For the purposes of our implementation, we will take a look at some data with 2 attributes for simplicity. We will then look at an example with more dimensions. To get us started, we will use a dataset we have prepared and it is available here with the name kmeans_blobs.csv. The data set contains 4 columns with the following information:
- ID: A unique identifier for the observation
- x: Attribute corresponding to an x coordinate
- y: Attribute corresponding to a y coordinate
- Cluster: An identifier for the cluster the observation belongs to
We will discard column 4 for our analysis, but it may be useful to check the results of the application of k-means. We will do this in our second example later on. Let us start by reading the dataset:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
%matplotlib inline
blobs = pd.read_csv('kmeans_blobs.csv')
colnames = list(blobs.columns[1:-1])
blobs.head()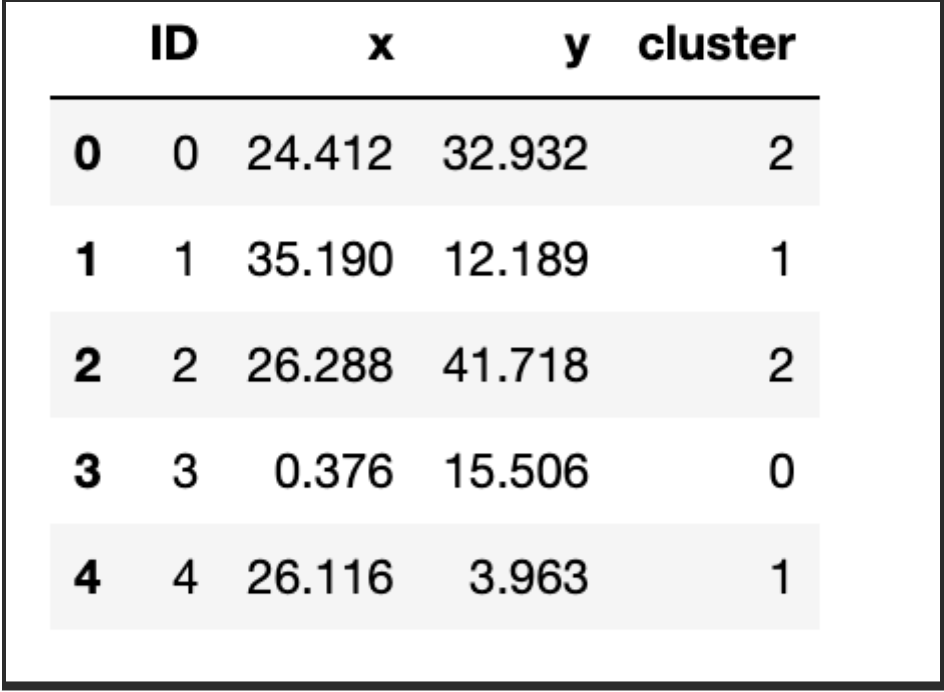
Let us look at the observations in the dataset. We will use the Cluster column to show the different groups that are present in the dataset. Our aim will be to see if the application of the algorithm reproduces closely the groupings.
customcmap = ListedColormap(["crimson","mediumblue","darkmagenta"])
fig, ax = plt.subplots(figsize=(8, 6))
plt.scatter(x=blobs['x'], y=blobs['y'], s=150,
c=blobs['cluster'].astype('category'),
cmap = customcmap)
ax.set_xlabel(r'x', fontsize=14)
ax.set_ylabel(r'y', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
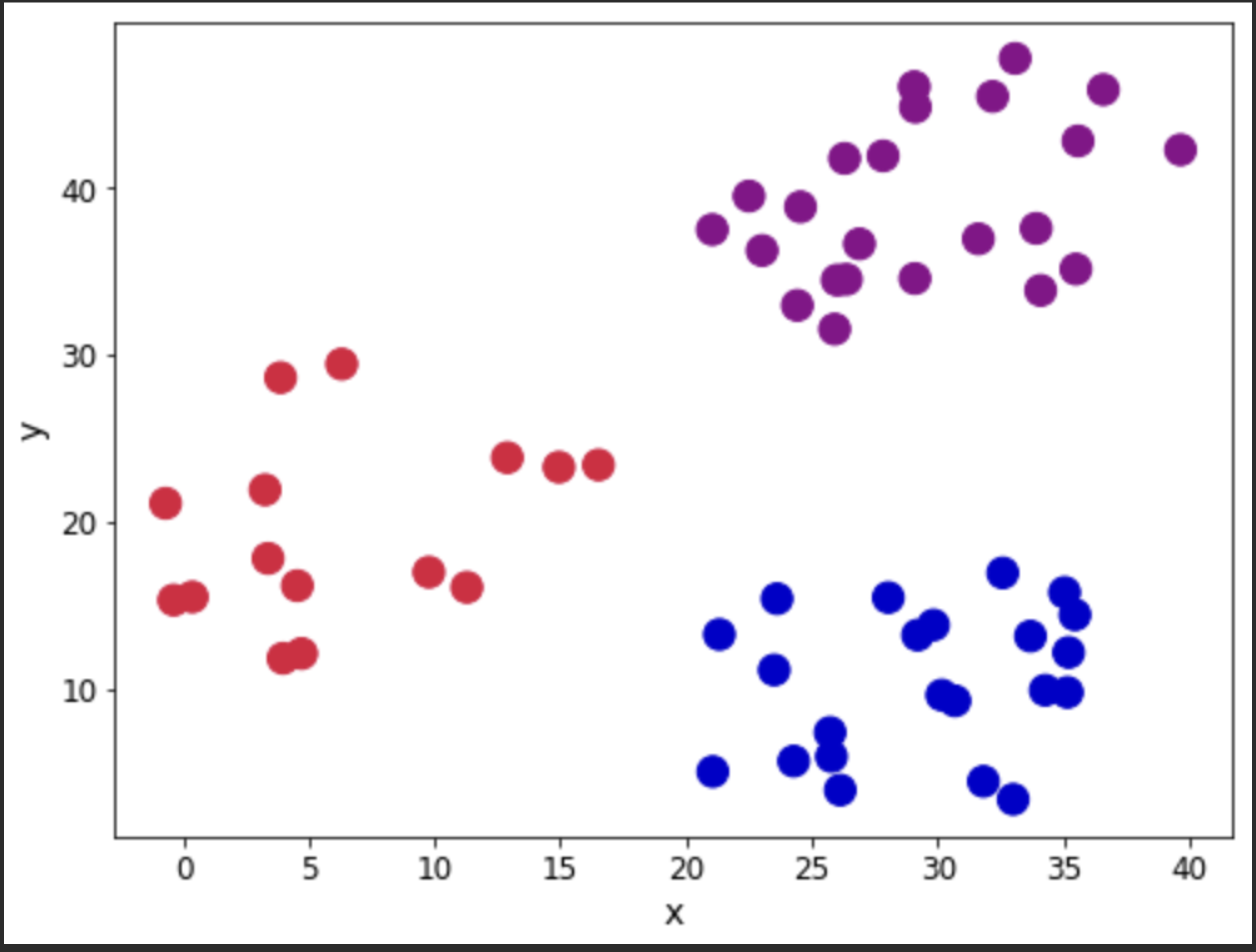
Let's now look at our recipe.
Steps 1 and 2 - Define k and initiate the centroids
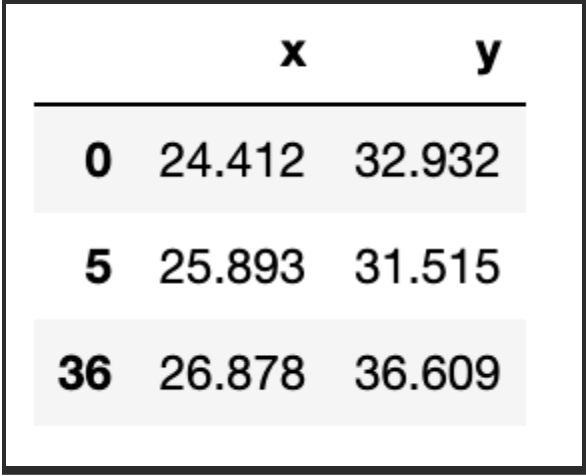
First, we need 1) to decide how many groups we have and 2) assign the initial centroids randomly. In this case, let us consider k=3, and as for the centroids, well, they have to be in the same range as the dataset itself. So, one option is to randomly pick k observations and use their coordinates to initialise the centroids:
def initiate_centroids(k, dset):
'''
Select k data points as centroids
k: number of centroids
dset: pandas dataframe
'''
centroids = dset.sample(k)
return centroids
np.random.seed(42)
k=3
df = blobs[['x','y']]
centroids = initiate_centroids(k, df)
centroids
Step 3 - Calculate distance
We now need to calculate the distance between each of the centroids and the data points. We will assign the data point to the centroid that gives us the minimum error. Let us create a function to calculate the root of square errors:
def rsserr(a,b):
'''
Calculate the root of sum of squared errors.
a and b are numpy arrays
'''
return np.square(np.sum((a-b)**2))Let us pick a data point and calculate the error so we can see how this works in practice. We will use a point, which is in fact one of the centroids we picked above. As such, we expect that the error for that point and the third centroid is zero. We therefore would assign that data point to the second centroid. Let’s take a look:
for i, centroid in enumerate(range(centroids.shape[0])):
err = rsserr(centroids.iloc[centroid,:], df.iloc[36,:])
print('Error for centroid {0}: {1:.2f}'.format(i, err))
Error for centroid 0: 384.22
Error for centroid 1: 724.64
Error for centroid 2: 0.00Step 4 - Assign centroids
We can use the idea from Step 3 to create a function that helps us assign the data points to corresponding centroids. We will calculate all the errors associated to each centroid, and then pick the one with the lowest value for assignation:
def centroid_assignation(dset, centroids):
'''
Given a dataframe `dset` and a set of `centroids`, we assign each
data point in `dset` to a centroid.
- dset - pandas dataframe with observations
- centroids - pa das dataframe with centroids
'''
k = centroids.shape[0]
n = dset.shape[0]
assignation = []
assign_errors = []
for obs in range(n):
# Estimate error
all_errors = np.array([])
for centroid in range(k):
err = rsserr(centroids.iloc[centroid, :], dset.iloc[obs,:])
all_errors = np.append(all_errors, err)
# Get the nearest centroid and the error
nearest_centroid = np.where(all_errors==np.amin(all_errors))[0].tolist()[0]
nearest_centroid_error = np.amin(all_errors)
# Add values to corresponding lists
assignation.append(nearest_centroid)
assign_errors.append(nearest_centroid_error)
return assignation, assign_errorsLet us add some columns to our data containing the centroid assignations and the error incurred. Furthermore, we can use this to update our scatter plot showing the centroids (denoted with squares) and we colour the observations according to the centroid they have been assigned to:
df['centroid'], df['error'] = centroid_assignation(df, centroids)
df.head()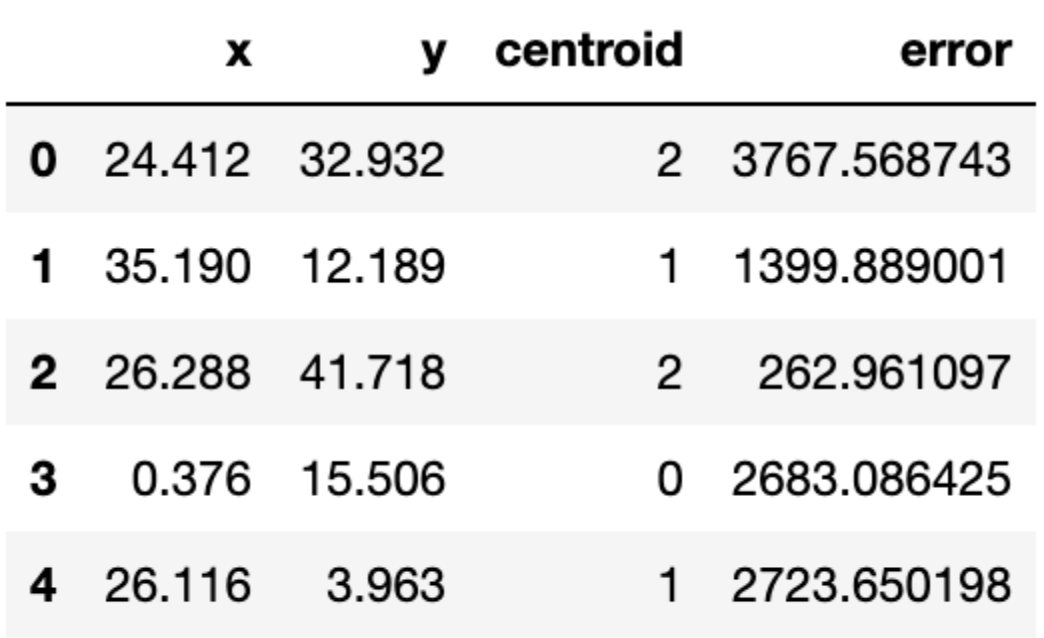
fig, ax = plt.subplots(figsize=(8, 6))
plt.scatter(df.iloc[:,0], df.iloc[:,1], marker = 'o',
c=df['centroid'].astype('category'),
cmap = customcmap, s=80, alpha=0.5)
plt.scatter(centroids.iloc[:,0], centroids.iloc[:,1],
marker = 's', s=200, c=[0, 1, 2],
cmap = customcmap)
ax.set_xlabel(r'x', fontsize=14)
ax.set_ylabel(r'y', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()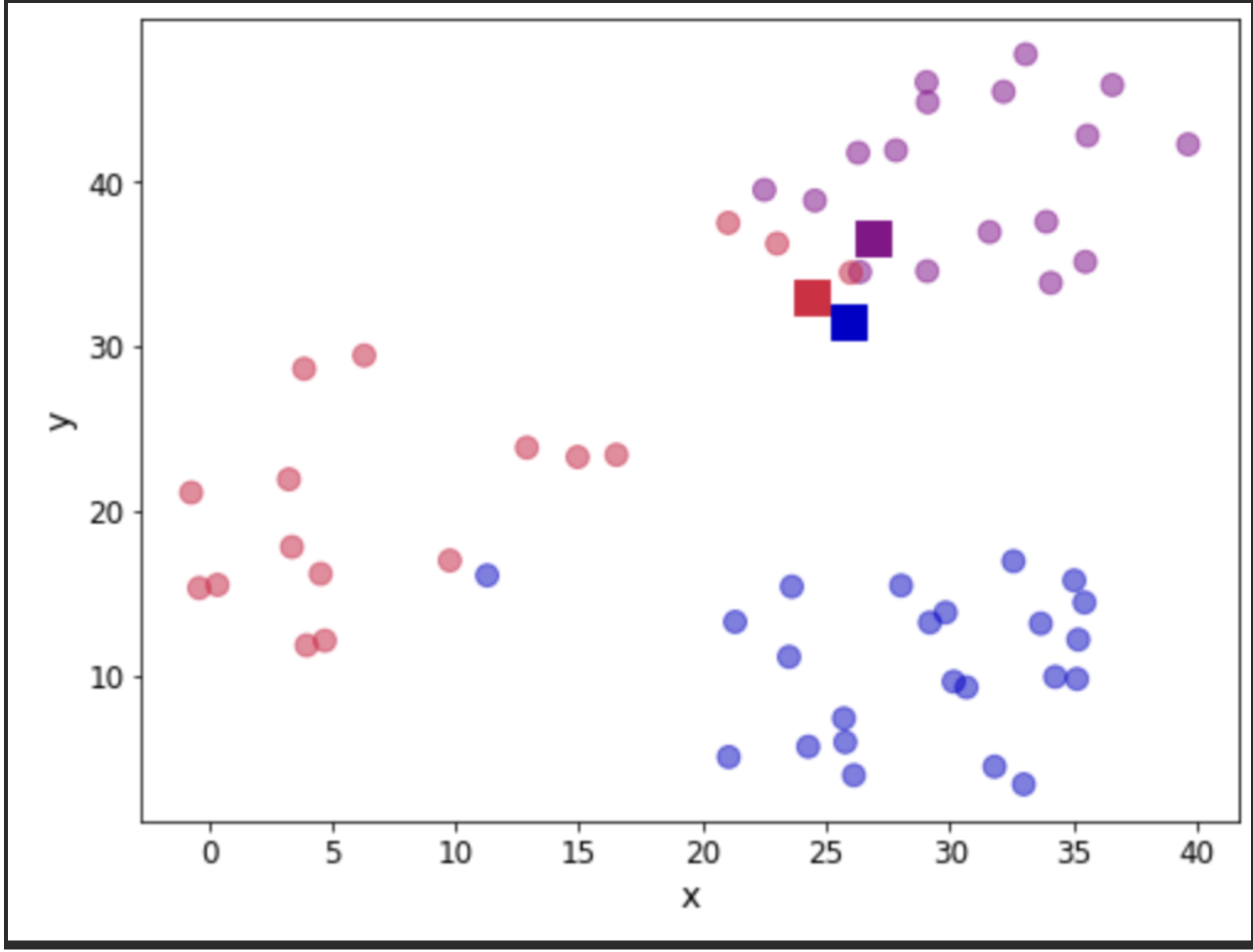
Let us see the total error by adding all the contributions. We will take a look at this error as a measure of convergence. In other words, if the error does not change, we can assume that the centroids have stabilised their location and we can terminate our iterations. In practice, we need to be mindful of having found a local minimum (outside the scope of this post).
print("The total error is {0:.2f}".format(df['error'].sum()))
The total error is 11927659.01Step 5 - Update centroid location
Now that we have a first attempt at defining our clusters, we need to update the position of the k centroids. We do this by calculating the mean of the position of the observations assigned to each centroid. Let take a look:
centroids = df.groupby('centroid').agg('mean').loc[:, colnames].reset_index(drop = True)
centroids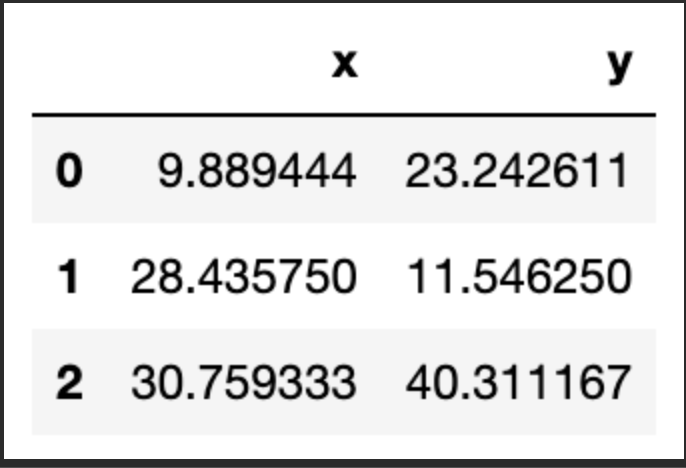
We can verify that the position has been updated. Let us look again at our scatter plot:
fig, ax = plt.subplots(figsize=(8, 6))
plt.scatter(df.iloc[:,0], df.iloc[:,1], marker = 'o',
c=df['centroid'].astype('category'),
cmap = customcmap, s=80, alpha=0.5)
plt.scatter(centroids.iloc[:,0], centroids.iloc[:,1],
marker = 's', s=200,
c=[0, 1, 2], cmap = customcmap)
ax.set_xlabel(r'x', fontsize=14)
ax.set_ylabel(r'y', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()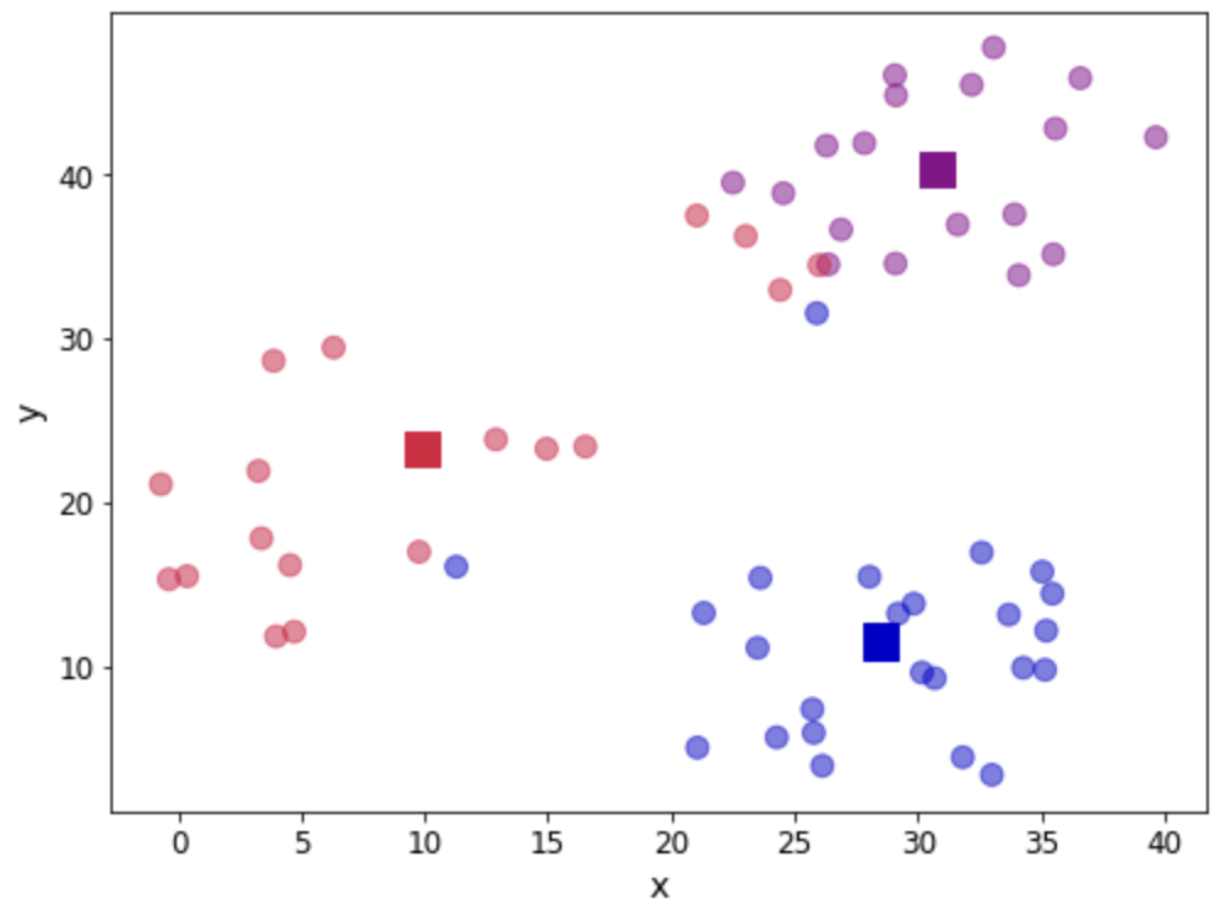
Step 6 - Repeat steps 3-5
Now we go back to calculate the distance to each centroid, assign observations and update the centroid location. This calls for a function to encapsulate the loop:
def kmeans(dset, k=2, tol=1e-4):
'''
K-means implementationd for a
`dset`: DataFrame with observations
`k`: number of clusters, default k=2
`tol`: tolerance=1E-4
'''
# Let us work in a copy, so we don't mess the original
working_dset = dset.copy()
# We define some variables to hold the error, the
# stopping signal and a counter for the iterations
err = []
goahead = True
j = 0
# Step 2: Initiate clusters by defining centroids
centroids = initiate_centroids(k, dset)
while(goahead):
# Step 3 and 4 - Assign centroids and calculate error
working_dset['centroid'], j_err = centroid_assignation(working_dset, centroids)
err.append(sum(j_err))
# Step 5 - Update centroid position
centroids = working_dset.groupby('centroid').agg('mean').reset_index(drop = True)
# Step 6 - Restart the iteration
if j>0:
# Is the error less than a tolerance (1E-4)
if err[j-1]-err[j]<=tol:
goahead = False
j+=1
working_dset['centroid'], j_err = centroid_assignation(working_dset, centroids)
centroids = working_dset.groupby('centroid').agg('mean').reset_index(drop = True)
return working_dset['centroid'], j_err, centroidsOK, we are now ready to apply our function. We will clean our dataset first and let the algorithm run:
np.random.seed(42)
df['centroid'], df['error'], centroids = kmeans(df[['x','y']], 3)
df.head()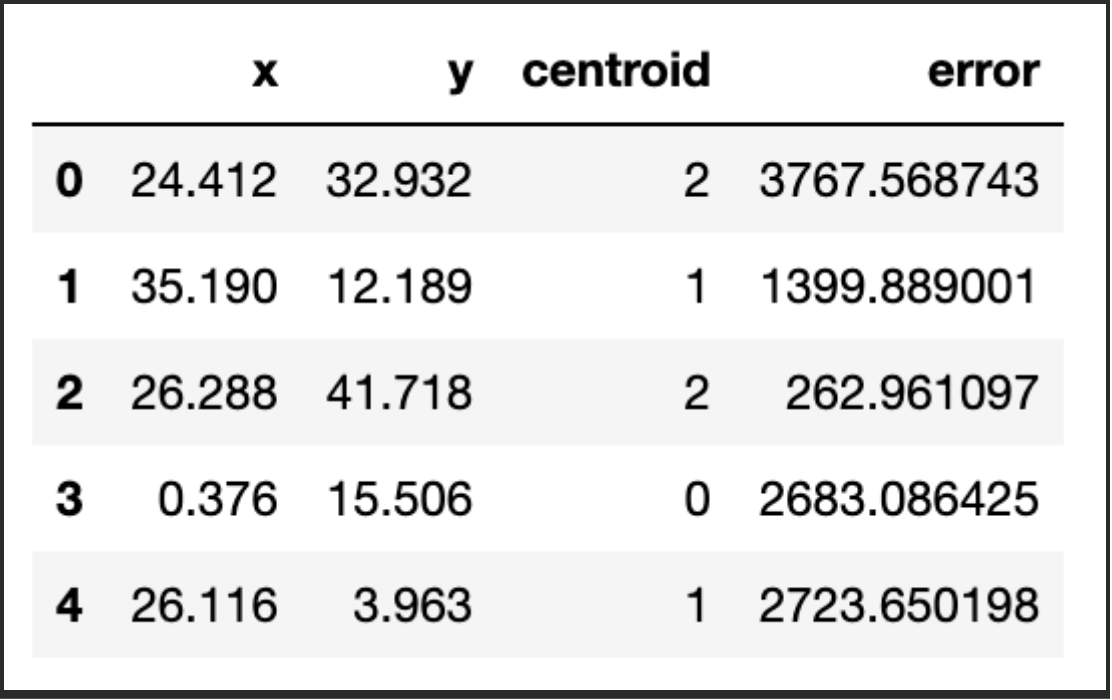
Let us see the location of the final centroids:
centroids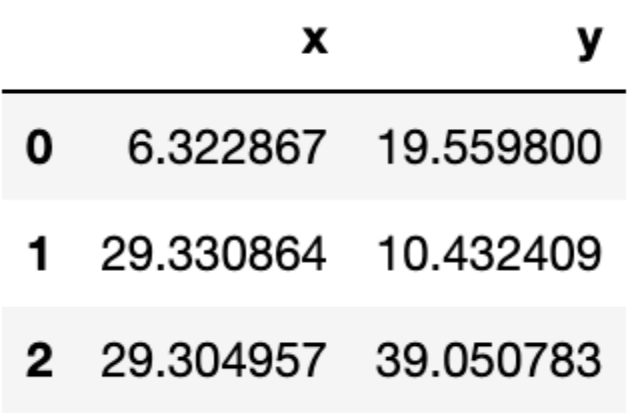
And in a graphical way, let us see our clusters:
fig, ax = plt.subplots(figsize=(8, 6))
plt.scatter(df.iloc[:,0], df.iloc[:,1], marker = 'o',
c=df['centroid'].astype('category'),
cmap = customcmap, s=80, alpha=0.5)
plt.scatter(centroids.iloc[:,0], centroids.iloc[:,1],
marker = 's', s=200, c=[0, 1, 2],
cmap = customcmap)
ax.set_xlabel(r'x', fontsize=14)
ax.set_ylabel(r'y', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()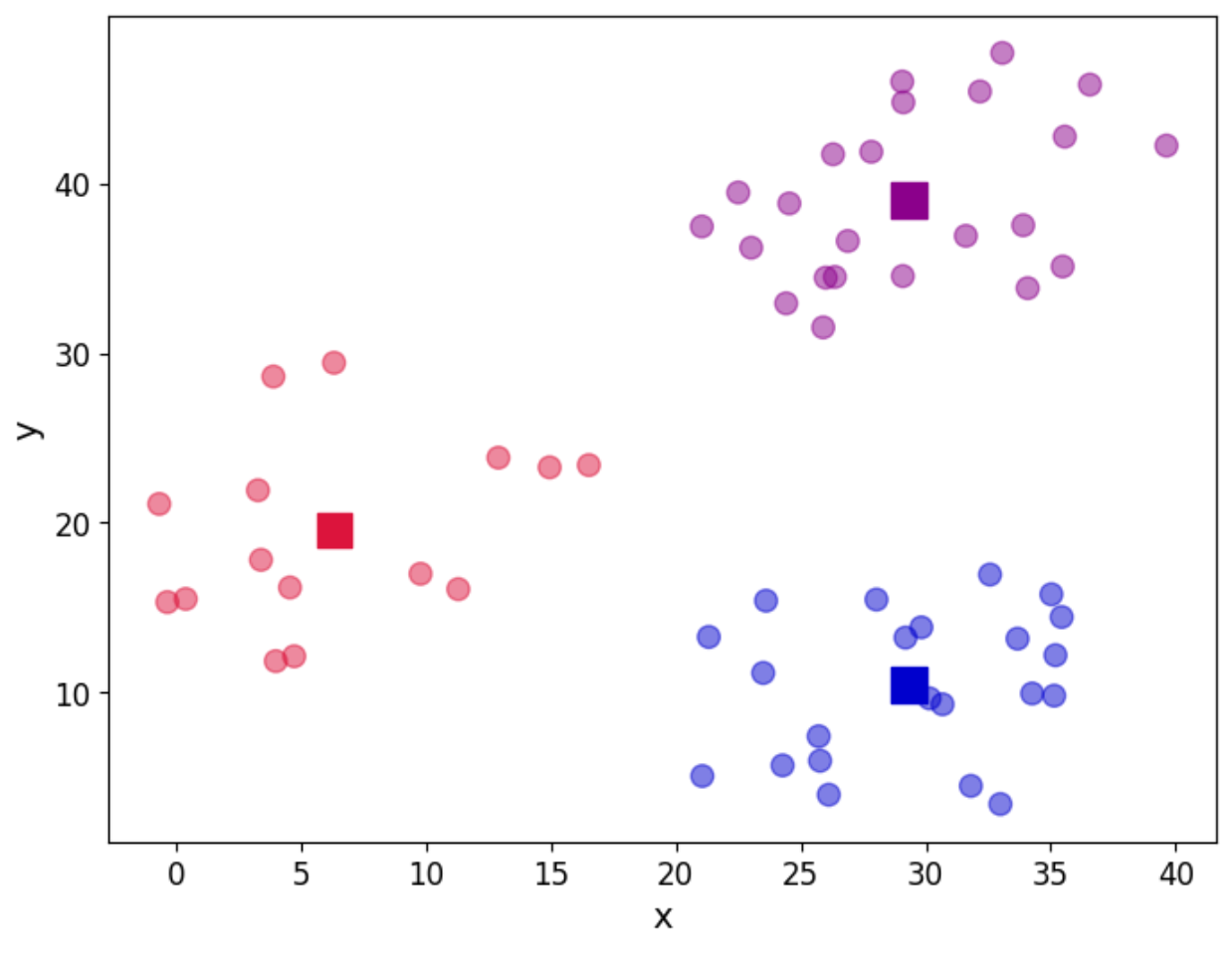
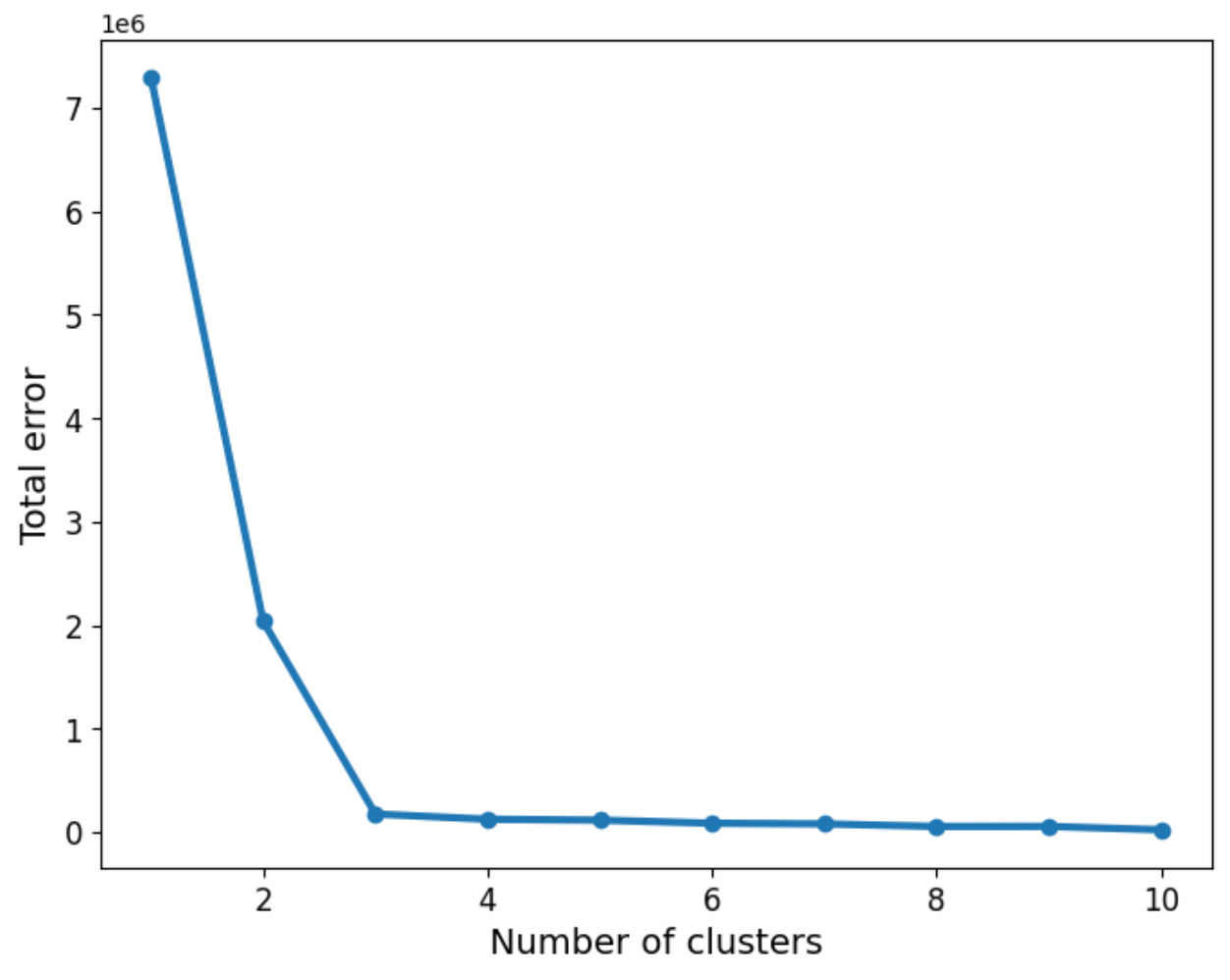
As we can see, the three groups have been obtained. In this particular example, the data is such that the distinction between the groups is clear. However, we may not be as lucky in every case. So the question about how many groups there are still remains. We can use a screen plot to help us with the error minimisation by looking at running the algorithm with a sequence k=1,2,3,4,...and look for the “elbow” in the plot indicating a good number of clusters to use:
err_total = []
n = 10
df_elbow = blobs[['x','y']]
for i in range(n):
_, my_errs, _ = kmeans(df_elbow, i+1)
err_total.append(sum(my_errs))
fig, ax = plt.subplots(figsize=(8, 6))
plt.plot(range(1,n+1), err_total, linewidth=3, marker='o')
ax.set_xlabel(r'Number of clusters', fontsize=14)
ax.set_ylabel(r'Total error', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()We can now apply the “elbow rule” which is a heuristic to help us determine the number of clusters. If we think of the line shown above as depicting an arm, then the “elbow” is the point of inflection. In this case the “elbow” is located between 2 and 4 clusters, giving us an indication that choosing 3 is a good fit.
Using Scikit-learn
We have seen how to make an initial implementation of the algorithm, but in many cases, you may want to stand on the shoulders of giants and use other tried and tested modules to help you with your machine learning work. In this case, Scikit-learn is a good choice, and it has a very nice implementation for k-means.
If you want to know more about the algorithm and its evaluation, you can take a look at Chapter 5 of Data Science and Analytics with Python, where I use a wine dataset for the discussion.
In this case, we will show how k-means can be implemented in a couple of lines of code using the well-known Iris dataset. We can load it directly from Scikit-learn and we will shuffle the data to ensure the points are not listed in any particular order.
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.utils import shuffle
# import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
names = iris.feature_names
X, y = shuffle(X, y, random_state=42)We can call the KMeans implementation to instantiate a model and fit it. The parameter n_clusters is the number of clusters k. In the example below we request 3 clusters:
model = KMeans(n_clusters=3, random_state=42)
iris_kmeans = model.fit(X)That’s it! We can look at the labels that the algorithm has provided as follows:
iris_kmeans.labels_
array([1, 0, 2, 1, 1, 0, 1, 2, 1, 1, 2, 0, 0, 0, 0, 1, 2, 1, 1, 2, 0, 1,
0, 2, 2, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0,
0, 1, 1, 2, 1, 2, 1, 2, 1, 0, 2, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0,
1, 2, 0, 1, 1, 0, 1, 1, 1, 1, 2, 1, 0, 1, 2, 0, 0, 1, 2, 0, 1, 0,
0, 1, 1, 2, 1, 2, 2, 1, 0, 0, 1, 2, 0, 0, 0, 1, 2, 0, 2, 2, 0, 1,
1, 1, 1, 2, 0, 2, 1, 2, 1, 1, 1, 0, 1, 1, 0, 1, 2, 2, 0, 1, 2, 2,
0, 2, 0, 2, 2, 2, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 1, 2], dtype=int32)
In order to make a comparison, let us reorder the labels:
y = np.choose(y, [1, 2, 0]).astype(int)
y
array([2, 1, 0, 2, 2, 1, 2, 0, 2, 2, 0, 1, 1, 1, 1, 2, 0, 2, 2, 0, 1, 0,
1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 2, 1, 1, 0, 2, 1, 1, 1, 0, 2, 2, 1,
1, 2, 0, 0, 2, 0, 2, 0, 2, 1, 0, 2, 1, 1, 1, 2, 0, 1, 1, 1, 2, 1,
2, 0, 1, 2, 0, 1, 0, 0, 2, 2, 0, 2, 1, 2, 0, 1, 1, 2, 2, 1, 0, 1,
1, 2, 2, 0, 2, 0, 0, 2, 1, 1, 0, 0, 1, 1, 1, 2, 0, 1, 0, 0, 1, 2,
2, 0, 2, 0, 1, 0, 2, 0, 2, 2, 2, 1, 2, 2, 1, 2, 0, 0, 1, 2, 0, 0,
1, 0, 1, 2, 0, 0, 2, 0, 2, 2, 0, 0, 1, 2, 0, 1, 2, 0])
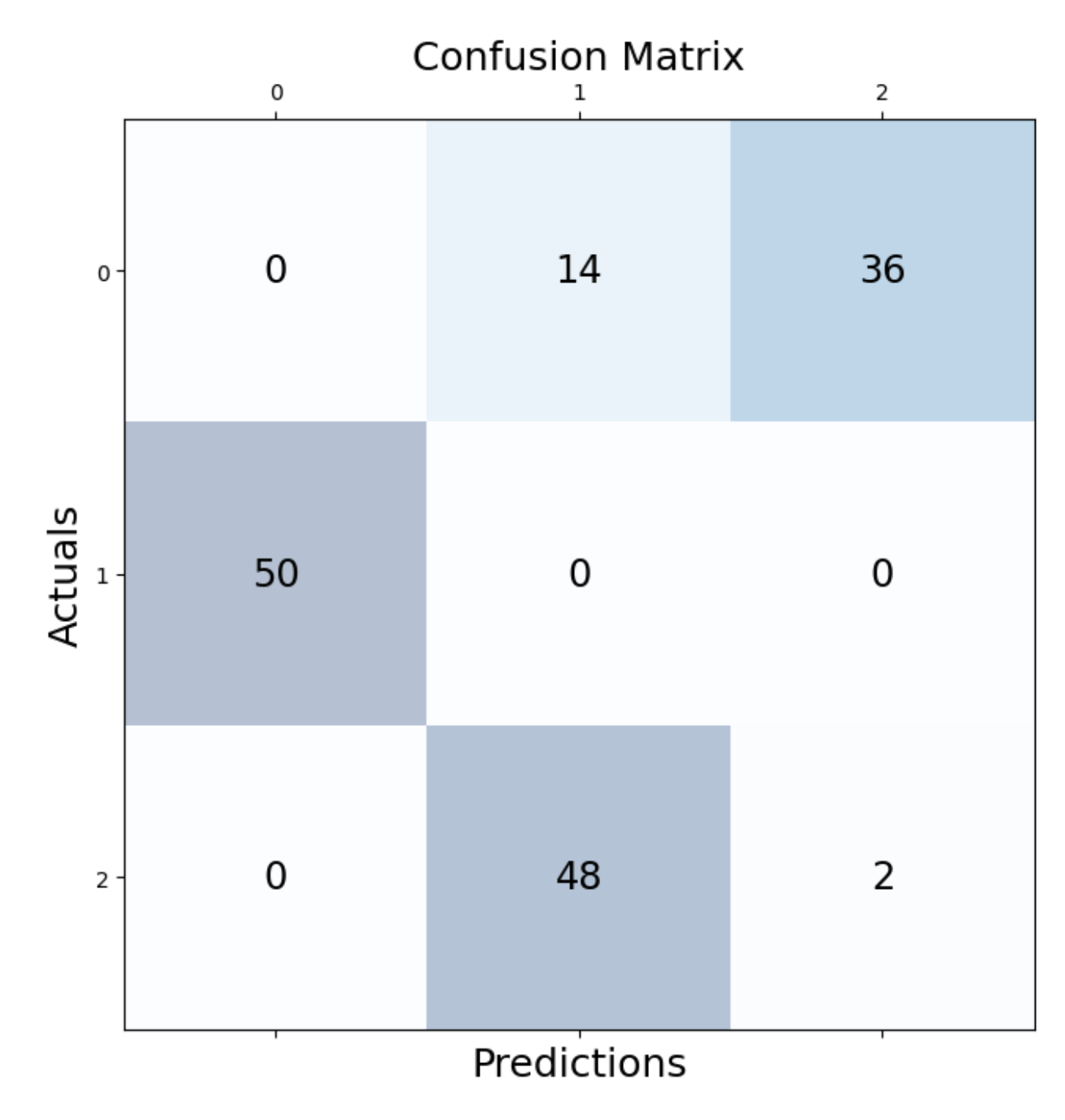
We can check how many observations were correctly assigned. We do this with the help of a confusion matrix:
from sklearn.metrics import confusion_matrix
conf_matrix=confusion_matrix(y, iris_kmeans.labels_)
fig, ax = plt.subplots(figsize=(7.5, 7.5))
ax.matshow(conf_matrix, cmap=plt.cm.Blues, alpha=0.3)
for i in range(conf_matrix.shape[0]):
for j in range(conf_matrix.shape[1]):
ax.text(x=j, y=i,s=conf_matrix[i, j], va='center',
ha='center', size='xx-large')
plt.xlabel('Predictions', fontsize=18)
plt.ylabel('Actuals', fontsize=18)
plt.title('Confusion Matrix', fontsize=18)
plt.show()As we can see, most of the observations were correctly identified. In particular those for cluster 1 seem to all have been captured.
Let’s look at the location of the final clusters:
iris_kmeans.cluster_centers_
array([[5.006 , 3.428 , 1.462 , 0.246 ],
[5.9016129 , 2.7483871 , 4.39354839, 1.43387097],
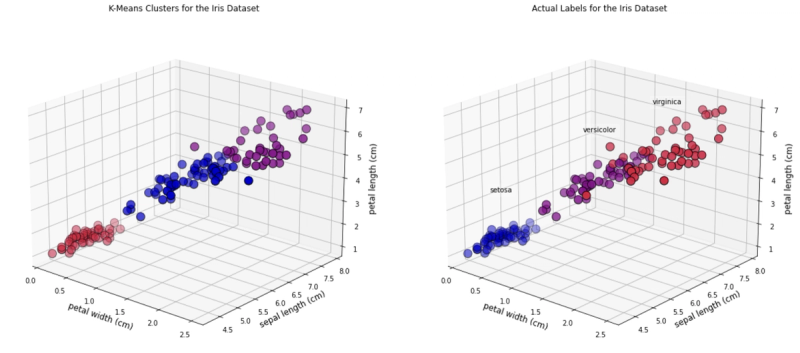
[6.85 , 3.07368421, 5.74210526, 2.07105263]])And we can look at some 3D graphics. In this case we will plot the following features:
• Petal width• Sepal length• Petal length
As you can see, there are a few observations that differ in colour between the two plots.
fig = plt.figure(figsize=(20, 10))
ax1 = fig.add_subplot(1, 2, 1, projection='3d')
ax1.scatter(X[:, 3], X[:, 0], X[:, 2],
c=iris_kmeans.labels_.astype(float),
edgecolor="k", s=150, cmap=customcmap)
ax1.view_init(20, -50)
ax1.set_xlabel(names[3], fontsize=12)
ax1.set_ylabel(names[0], fontsize=12)
ax1.set_zlabel(names[2], fontsize=12)
ax1.set_title("K-Means Clusters for the Iris Dataset", fontsize=12)
ax2 = fig.add_subplot(1, 2, 2, projection='3d')
for label, name in enumerate(['virginica','setosa','versicolor']):
ax2.text3D(
X[y == label, 3].mean(),
X[y == label, 0].mean(),
X[y == label, 2].mean() + 2,
name,
horizontalalignment="center",
bbox=dict(alpha=0.2, edgecolor="w", facecolor="w"),
)
ax2.scatter(X[:, 3], X[:, 0], X[:, 2],
c=y, edgecolor="k", s=150,
cmap=customcmap)
ax2.view_init(20, -50)
ax2.set_xlabel(names[3], fontsize=12)
ax2.set_ylabel(names[0], fontsize=12)
ax2.set_zlabel(names[2], fontsize=12)
ax2.set_title("Actual Labels for the Iris Dataset", fontsize=12)
fig.show()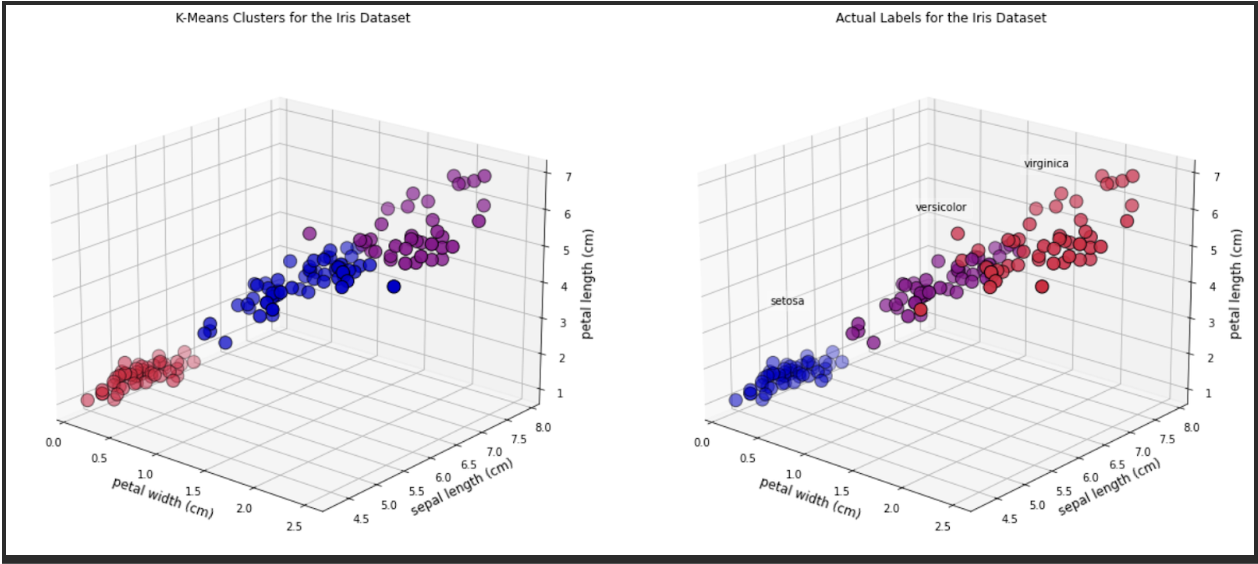
Summary
In this post we have explained the ideas behind the k-means algorithm and provided a simple implementation of these ideas in Python. I hope you agree that it is a very straightforward algorithm to understand and in case you want to use a more robust implementation, Scikit-learn has us covered. Given its simplicity, k-means is a very popular choice for starting up with clustering analysis.

Dr Jesus Rogel-Salazar is a Research Associate in the Photonics Group in the Department of Physics at Imperial College London. He obtained his PhD in quantum atom optics at Imperial College in the group of Professor Geoff New and in collaboration with the Bose-Einstein Condensation Group in Oxford with Professor Keith Burnett. After completion of his doctorate in 2003, he took a postdoc in the Centre for Cold Matter at Imperial and moved on to the Department of Mathematics in the Applied Analysis and Computation Group with Professor Jeff Cash.
RELATED TAGS
SHARE


