Density-Based Clustering
What is Density-Based Clustering?
Density-Based Clustering refers to unsupervised machine learning methods that identify distinctive clusters in the data, based on the idea that a cluster/group in a data space is a contiguous region of high point density, separated from other clusters by sparse regions. The data points in the separating, sparse regions are typically considered noise/outliers.
Cluster Analysis is an important problem in data analysis. Data scientists use clustering to identify malfunctioning servers, group genes with similar expression patterns, identify anomalies in biomedical images, and perform various other applications.
There are many families of data clustering algorithms, and you may be familiar with the most popular ones: k-Means and DBSCAN. K-Means determines k centroids - the center of a data cluster - in the data and clusters points by assigning them to the nearest centroid.
Clustering Application with K-Means
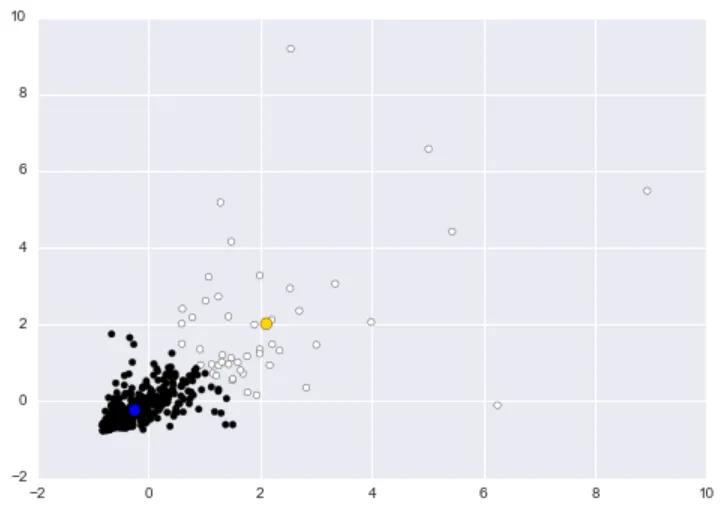
In the above dataset, we ran k-Means with two clusters. The big blue dot represents the centroid for the black cluster, and the big gold dot represents the centroid for the white cluster.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is the most well-known density-based clustering algorithm, first introduced in 1996 by Ester et. al. Due to its importance in both theory and applications, this algorithm is one of three algorithms awarded the Test of Time Award at the KDD conference in 2014.
Additional Resources