XGBoost
What is XGBoost?
XGBoost is an open source, ensemble machine learning algorithm that utilizes a high-performance implementation of gradient boosted decision trees. An underlying C++ codebase combined with a Python interface sitting on top makes XGBoost a very fast, scalable, and highly usable library.
XGBoost is an algorithm that has recently been dominating applied machine learning (ML) and Kaggle competitions for structured or tabular data. The XGBoost algorithm was developed as a research project at the University of Washington, and presented at the SIGKDD Conference in 2016. Since its introduction, this algorithm has not only been credited with winning numerous Kaggle competitions, but also for being the algorithm powering several cutting-edge industry applications. As a result, there is a strong community of data scientists contributing to the XGBoost open source projects with ~500 contributors and ~5000 commits on GitHub.
To understand how XGBoost works, you need to understand decision trees, ensembles, boosting, and gradient boosting.
Decision Tree Illustration from Titanic Survival Rates
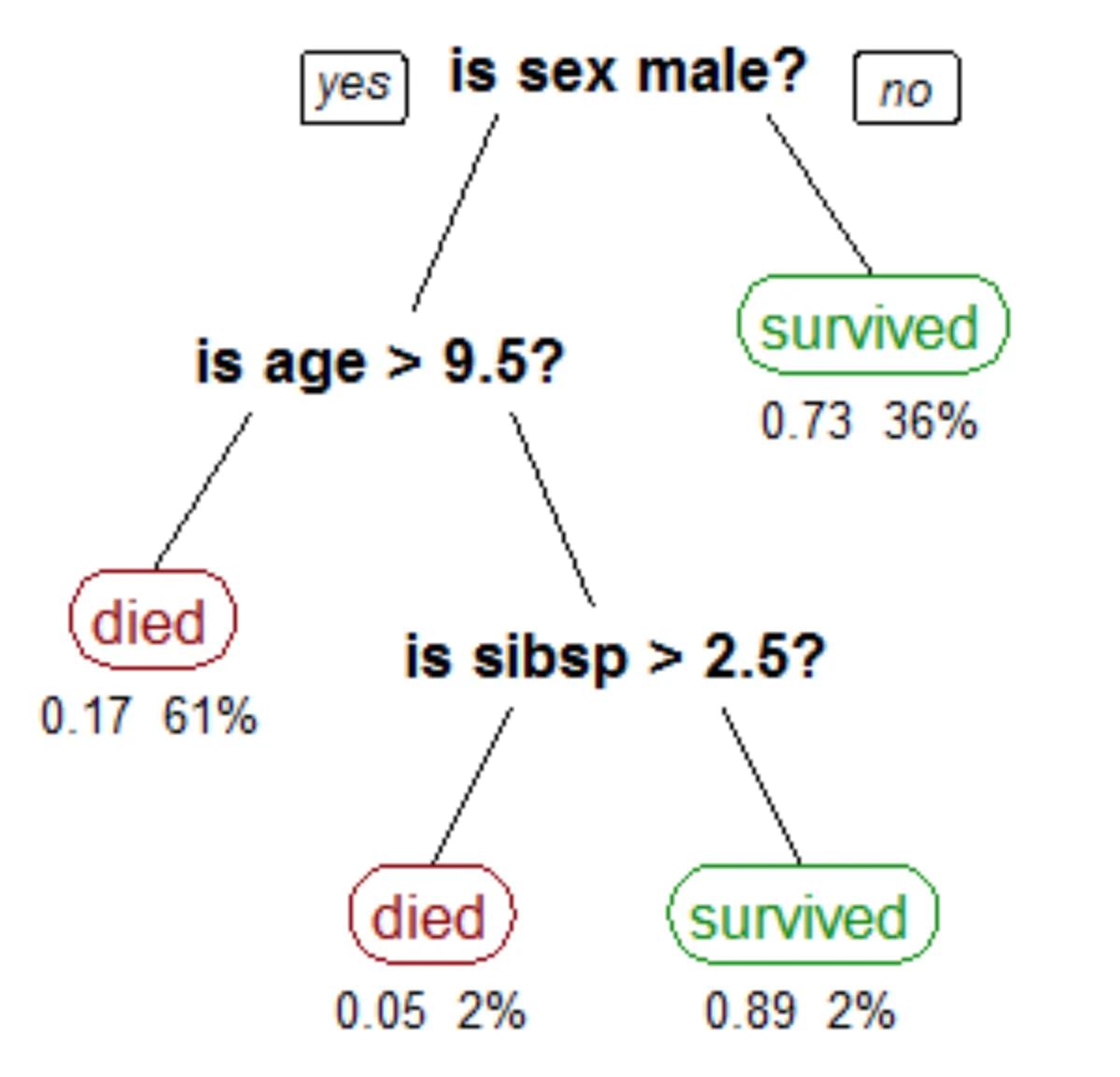
Source: Vighnesh Tiwari
Decision trees are a type of ML algorithm that have a tree-like graph structure that is used for prediction. The leaves in a decision tree correspond to target classes, and each node in a decision tree represents an attribute. The popular electronic game 20Q and Alexa skill Twenty Questions are both examples of a decision tree in action.
Ensembles refer to a group of people or things. Ensembling is an ML technique that involves combining several machine learning models to build a single powerful predictive model to get optimal results.
Boosting is an ensemble-based learning algorithm which involves training ML models sequentially one after the other, and in each iteration the new model is trained to correct the errors made by the previous ones.
Gradient Boosting is a boosting technique wherein in each iteration the new models are trained to predict the residuals (i.e., errors) of prior models.
XGBoost uses more accurate approximations than Gradient Boosting by employing second-order gradients and advanced regularization. It seeks to minimize the following objective function:
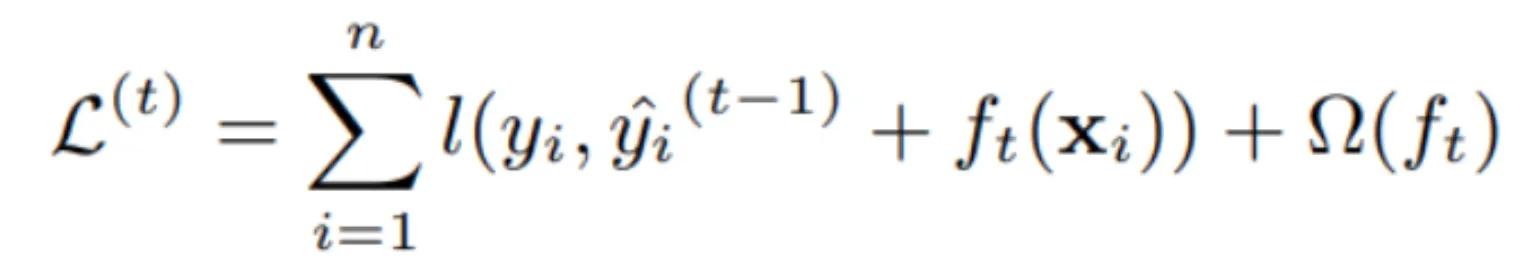
Read the original paper, XGBoost: A Scalable Tree Boosting System, for more details.
Implementing XGBoost
XGBoost can be used to solve regression, classification, ranking, and user-defined prediction problems. It runs on Windows, Linux and macOS, and supports all major programming languages. The distributed version of XGBoost is designed to be portable to various environments, and can be ported to any cluster that supports rabit. You can directly run XGBoost on Yarn and Kubernetes; Mesos and other resource allocation engines can be supported as well.
Due to the nature of an ensemble model, you have to be careful about overfitting. The eta parameter in XGBoost gives you a chance to prevent this overfitting. The eta can be intuitively thought of as a learning rate. Rather than simply adding the predictions of new trees to the ensemble with full weight, the eta will be multiplied by the residuals being added to reduce their weight. This reduces the complexity of the overall model and the likelihood of overfitting. It is common to have small eta values in the range of 0.1 to 0.3.


